|
|
|
|
|
|
|
|
Du kannst die if-Abfrage in Mensch getgröße() machen, musst dann aber in den Methoden der abgeleiteten Klassen die Methode der Basisklasse (Mensch) aufrufen. Sichtwort super.
|
|
|
|
|
|
|
|
|

|
Alles klar, danke.  Hat geklappt. Hat geklappt.
|
|
|
|
|
|
|
|
|
|
|
|
Sollte man das nicht eigentlich eher in den Konstruktor packen, sodass man gar keinen Menschen mit negativer Groesse und/oder Gewicht erzeugen kann?
|
|
|
|
|
|
|
|
|
|
|
|
Ja. Dabei aber bitte aufpassen, dass die Exception gleich geworfen werden sollte, da man ansonsten "kaputte" Objekte erzeugt. Mehr dazu.
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von MCignaz
Sollte man das nicht eigentlich eher in den Konstruktor packen, sodass man gar keinen Menschen mit negativer Groesse und/oder Gewicht erzeugen kann?
| |
Richtig, war aber nicht die Aufgabenstellung. Würde ich als Tutor allerdings trotzdem akzeptieren, weil's die bessere Lösung in dem Kontext ist.
|
|
|
|
|
|
|
|
|
|
|
Naja, wenn ich diese unvollständigen Code-Schnippsel sehe, fallen mir gleich noch ein paar Dinge auf...
- Du hast eine normale Klasse Mensch, die leere Methoden hat. Davon bildest du Subklassen... Normalerweise macht man das nicht so, meiner Meinung nach. So kann man bei dir ein Objekt Mensch instanziieren, welches aber überhaupt nichts kann (alle Methoden leer). Auch wenn die Methoden nur printlns machen... warum heißen sie "getXXX"? Getter sind in Java ein weithin akzeptiertes (und oft verfluchtes) Pattern, die eben einen Wert zurückgeben. Wie wäre es mit "printXXX"?
Üblicherweise benutzt man zwei Wege:
* Mensch wird ein Interface, mit den Methoden die du brauchst. Dadurch zwingst du (zumindest in Java 7 ohne Default-Implementierungen) die implementierenden Klassen, eben auch die Methoden zu implementieren.
* Mensch wird eine abstrakte Klasse. Durch abstrakte Methoden darin kannst ebenfalls die Subklassen dazu zwingen, die Methoden zu implementieren.
Welchen Weg man wählt, hängt ein wenig von dem zu erreichenden Ziel ab. Meistens benutzt man abstrakte Klassen, wenn man einen Teil der Funktionalität in dieser Klasse schon zur Verfügung stellen will. Quasi 90% der Methoden und Abläufe überall gleich sind, aber die letzten 10% sollen die Subklassen doch bitte mal selber implementieren. Allerdings ist diese Art der Vererbung eher unbeliebt in Java. Das hat verschiedene Gründe und es gibt lange Diskussionen von klugen Leuten dazu, wenn dich das interessiert such mal nach "You should avoid implementation inheritance whenever possible."
Deswegen würde ich dir eher raten, Interfaces zu benutzen, gerade weil dein Mensch ja gar nichts können muss, also auch keinerlei Funktionalität bereitstellt.
Mit Java 8 muss man die Argumente zumindest noch mal überdenken, aber das führt jetzt hier zu weit.
- Es gibt noch eine andere, sicherere Möglichkeit, auch wenn sie dir vielleicht zu kompliziert erscheint. Wenn du genau nachdenkst, ist es nicht das Problem, dass der Mensch eine negative Größe hat, sondern dass die Größe des Menschen negativ sein kann. Das ist ein kleiner aber feiner Unterschied, der dir aber einen Tipp zur Modellierung gibt.
Warum baust du nicht noch ein Objekt "Groesse" (nur als Beispiel), in dem du dich dann auch um die Exception kümmerst? Natürlich gibt dann mehrere Möglichkeiten auch die Exception geschickt zu verpacken, Exceptions in Konstruktoren sind eher unüblich.
So kann man nämlich, was ich persönlich viel besser finde, die Exception zu werfen wenn sie auftritt, nämlich beim Anlegen der Größe, und nicht erst wenn man die Größe abfragt. Solche Exception sind der Teufel und mach dein Programm unwartbar, sprich schlechter Stil. Hier gilt der Spruch "throw early, catch late".
Dein Fehler, zu dem die Exception passt, ist nunmal das Anlegen einer negativen Größe, nicht aber das Abfragen der Größe eines Menschen, die (dummerweise) negativ ist.
Das war das Wort zum Sonntag.
| | Zitat von csde_rats
| | Zitat von MCignaz
Sollte man das nicht eigentlich eher in den Konstruktor packen, sodass man gar keinen Menschen mit negativer Groesse und/oder Gewicht erzeugen kann?
| |
Richtig, war aber nicht die Aufgabenstellung. Würde ich als Tutor allerdings trotzdem akzeptieren, weil's die bessere Lösung in dem Kontext ist.
| |
"Besser" ist hier sehr subjektiv, je nachdem wie genau die Aufgabe gestellt ist und welche Möglichkeiten eingeräumt werden.
Ich würd es dir als Tutor um die Ohren hauen, allerdings mit Erklärung und Alternativen.
/e2: Herjee, je länger ich den Code sehe, desto mehr frage ich mich, ob ihr da wirklich so eine Scheiße bekommen habt, oder ob ihr die selber geschrieben habt... "public static" Variablen? Die großgeschrieben sind mit Umlauten drin? Geschlecht ist nicht static, Größe schon? Subklassen bilden, die die static!-Variablen der Oberklasse ändern? WTF? Dir ist schon klar, das jeder Mensch die gleiche Größe haben wird? Das ist alles schief und krumm 
|
|
[Dieser Beitrag wurde 3 mal editiert; zum letzten Mal von [smith] am 13.07.2014 20:12]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
@SilentAss : Ich bin jetzt mit dem Lesen bis Kapitel 9 im Srednicki. Ich glaube, ich sollte jetzt auch mal mit dem Rechnen anfangen, auch wenn meine Motivation bei den langen Termen sich in Grenzen hält... : Ich bin jetzt mit dem Lesen bis Kapitel 9 im Srednicki. Ich glaube, ich sollte jetzt auch mal mit dem Rechnen anfangen, auch wenn meine Motivation bei den langen Termen sich in Grenzen hält...
Bisher bin ich sehr angetan, dass auch die Gegenterme sehr früh erwähnt werden und entsprechend der frühen Erwähnung auch möglichst schonend erklärt werden. Ich glaube, danach durchaus etwas Ahnung von Renormierung bekommen zu können.
Nur: Ich muss halt mal rechnen...
...denk' mal drüber nach!
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von csde_rats
Viele Sachen haben ja eh nen Template irgendwo drin. Klar könnte ich dann nur das Template im Header lassen und den Rest in eine Implementierungsdatei packen, aber dann hätte ich die Definition der Klasse und ein bissl Implementierung im Header und noch ein bissl Implementierung separat.
| |
Weil am Wochenende darüber gestolpert bin und daran denken musste:
Man kann seit C++11 Klassen/Member/Funktionen in Header und Source aufteilen, wenn man vorher weiß, für welche Typen das Template stehen soll. Und zwar so (die Beispiele sind nicht zwangsläufig sinnvoll):
| |
| PHP: |
// foo.h
template <typename T>
class foo
{
T bar;
}
// foo.cpp
template class foo<char>;
template class foo<int>;
// bar.h
class bar
{
template <typename T>
T baar(const T& t);
}
// bar.cpp
template <typename T>
bar::baar(const T& t) { return t; }
template bar::baar<std::string>(const T& t);
// quux.h
template <typename T>
void quuux();
// quux.cpp
template <typename T>
void quux() { std::cout << "Hello p0T!" << std::endl; }
template quux<std::string>();
|
|
Wenn man jetzt in eine Situation kommt, in der diese Technik angewand wurde und man die cpp nicht ändern kann/darf, aber die Klasse/Methode/Funktion mit weiteren Typen braucht, von denen man weiß, dass sie kompatibel sind, dann kann man folgendes machen:
| |
| PHP: |
// quux-impl.cpp
#include "quux.cpp // Jaha, die cpp einbinden. Tut weh, muss aber.
template quux<char>();
|
|
|
|
[Dieser Beitrag wurde 2 mal editiert; zum letzten Mal von cms am 14.07.2014 22:56]
|
|
|
|
|
|
|
|
|
Nachdem jetzt endlich alle noch fehlenden Noten eingetragen sind, behauptet auch unser QIS das ich scheinfrei bin.

Weeee...jetzt nur noch ne Masterarbeit!
/: Ich merke gerade:
Masterarbeit 1,0 -> Gesamt 1,9
Masterarbeit 3,0 -> Gesamt 2,4
Das ist nicht so unbedingt motivierend, alles unter 2,5 reicht mir eigentlich
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Achsel-des-Bösen am 16.07.2014 10:25]
|
|
|
|
|
|
|
|
|
|
Finde ich den falschen Ansatz. Mach ne Arbeit auf die du stolz sein kannst!
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von B0rG*
Finde ich den falschen Ansatz. Mach ne Arbeit auf die du stolz sein kannst!
| |
Ich würde sagen, dass er eine Arbeit machen soll, die ihm Spaß macht, Stolz kommt bei mir erst an zweiter Stelle.
Aber wie auch immer, mach es für dich und nicht für irgendeine Note.
|
|
|
|
|
|
|
|
|
|
|
|
Ausserdem zählen die Noten der großen Arbeit(en) bei den Einstellenden (zumindest denen die mitdenken) mehr als irgendeine pimmelige Klausur. Würde ich mich schon reinhängen, noch ein Grund ein spannendes, aber schaffbares Thema zu suchen.
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von pinnback
| | Zitat von B0rG*
Finde ich den falschen Ansatz. Mach ne Arbeit auf die du stolz sein kannst!
| |
Ich würde sagen, dass er eine Arbeit machen soll, die ihm Spaß macht, Stolz kommt bei mir erst an zweiter Stelle.
Aber wie auch immer, mach es für dich und nicht für irgendeine Note.
| |
Dies.
Bachelorarbeit war mir damals ziemlich egal, war eine ziemlich beschissene Arbeit und ich schau auch nicht gerne darauf zurueck.
Master Arbeit war dann genau andersrum.
|
|
|
|
|
|
|
|
|

|
Die Physikarbeit war eigentlich superinteressant, leider nichts, was man da rausholen konnte. Die Mathearbeit war eigentlich auch interessant, leider hatte ich nicht die Zeit da was rauszuholen, geschweige denn mich in die Grundlagen wieder ausreichend einzuarbeiten.
Immer noch keine Note dafür. Langsam wird das doof...
Nun, aller höherer Humor fängt damit an, dass man die eigene Person nicht mehr ernst nimmt.
|
|
|
|
|
|
|
|
|
|
|
Oh, ich habe schon ein Thema das ich gut finde. Selbst ausgedacht und auch noch passenden zu der Firma wo ich das letzte Jahr als Werkstudent war.
Jetzt muss ich mich nur noch motivieren mal richtig anzufangen 
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von Wraith of Seth
@SilentAss: Ich bin jetzt mit dem Lesen bis Kapitel 9 im Srednicki. Ich glaube, ich sollte jetzt auch mal mit dem Rechnen anfangen, auch wenn meine Motivation bei den langen Termen sich in Grenzen hält...
Bisher bin ich sehr angetan, dass auch die Gegenterme sehr früh erwähnt werden und entsprechend der frühen Erwähnung auch möglichst schonend erklärt werden. Ich glaube, danach durchaus etwas Ahnung von Renormierung bekommen zu können.
Nur: Ich muss halt mal rechnen...
...denk' mal drüber nach!
| |
öhm Habe momentan viel zu tun, muss bis September Ergebnisse produzieren, aber das soll dich nicht davon abhalten hier Fragen zu stellen
|
|
|
|
|
|
|
|
|
|
|
Keine Angst, um Fragen zu stellen, müsste ich ja mehr als lesen...
Blow shit up, throw women through walls, got it.
|
|
|
|
|
|
|
|
|
|
|
Hallo!
Ausgang:
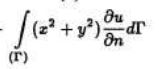
das du/dn entspricht im folgenden q, welches ich schon ermittelt habe.
In diesem Fall sind ja x und y die Koordinaten für einen Punkt der über den Rand läuft. Dann kann ich ja den Rand parametrisieren mittels s, welches auf den Randelementen entlangläuft und einer Funktion jeweils für x und y pro Randelement.

Oder? 
|
|
|
|
|
|
|
|
|
|
|
Ok, weil es mir gerade ein wenig im Kopf rumschwirrt: Bei meiner Mathe-Diplomarbeit geht es letzten Endes um das Lösen eines nichtlinearen Differentialgleichung, die ich mit finiten Differenzen approximiere und anschließend mit einem Newton-Verfahren beharke, um Lösungen zu bekommen. Ich weiß aus vorherigen Untersuchungen, dass ich etwa ein paar hundert Auswertungsstellen brauche - aber meine Verfahren konvergieren nicht mehr, sobald ich in diesen Bereich vorstoße. Davor passieren sehr unvorhersehbare Dinge, die ich als Überrest der noch nicht ausreichenden Feinheit interpretiere.
Was kann ich da machen? Ich stolper des öfteren über das Stichwort "Vorkonditionierung" und ich habe so ganz grob eine Ahnung, was da gemacht wird. Nur finde ich auch meistens nur einfache Beispiele gefolgt von abschließenden Absätzen der Art: "Für das jeweils vorliegende Problem einen passenden Vorkonditionierer finden, ist eine Wissenschaft für sich." Super. Irgendwas, was man da gezielt machen kann außer fröhlich vor sich hin probieren? Ich arbeite vor allem mit Scipy und Numpy und bin ständig damit beschäftigt, meine Daten an die jeweiligen Löser anzupassen - was ich ungefähr so interessant, spannend und abwechslungsreich finde, wie einer Tropfsteinhöhle beim Wachsen zuzusehen. Erst recht, weil ich dann immer stundenlang mit der Syntax kämpfe für völlige Trivialitäten.
Fällt jemandem mit mehr numerischer Erfahrung ein, was man da machen kann, um wieder Konvergenz zu bekommen?
Gentlemen. You can't fight in here. This is the War Room!
|
|
|
|
|
|
|
|
|
|
|
|
Die Aktienmärkte werden offensichtlich manipuliert: http://www.nanex.net/aqck2/4661.html Jetzt möchte ich aber doch mehr wissen. Kennt ihr noch andere gute Quellen/Studien zu dem Thema?
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von Wraith of Seth
Lösen eines nichtlinearen Differentialgleichung, die ich mit finiten Differenzen approximiere und anschließend mit einem Newton-Verfahren beharke, um Lösungen zu bekommen.
| |
Ok Differentialgleichungen numerisch lösen ist nicht ganz einfach und ich hoffe du hast dazu etwas Grundlagen gehört.
Ansonsten, deine Differentialgleichungen können steif (engl. stiff) sein bzw beliebig schlecht geartet / schwer numerisch lösbar.
Ich würde mir Gedanken über folgende Fragen machen:
- Sind meine bisher errechneten Ergebnisse überhaupt Lösungen oder ist das einfach numerischer Müll?
- Warum benutze ich ausgerechnet diese finite Differenzen Methode und nicht forwärts / rückwärts / central / höheres Runge Kutta / etc pp
- Liegt es vllt an meinen Verfahren?
- Liegt die nicht-Konvergenz des Newton Verfahrens am Startwert des Newtonverfahrens / dem Solver / dem Fehler der Differentialgleichungen / ...
- Könnte ich eine Lösung erkennen, falls am Ende wirklich eine rauskommt?
- Diskretisierung des Problems: Warum so? Was erwarte ich für eine Genauigkeit? Was für einen Fehler? Ort vs Zeit Diskretisierung?
Grob: Bei dem was zu machst kann alles falsch sein aber auch einiges richtig. Versuch dein Verfahren auf ein einfacheres / kleineres / reduziertes Problem anzuwenden und guck erstmal dass die Numerik allgemein läuft.
Zusatz Newtonverfahren: Implementierst du das per Hand? Evlt besser auf bestehende Packages zurückgreifen und mehrere funktionierende halbwegs robuste ausprobieren zu können. Es sei denn du bist komplett schmerzbefreit oder musst das so machen
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von LordFischkopf am 18.07.2014 21:52]
|
|
|
|
|
|
|
|
|
Laut Chef (=Betreuer) habe ich eine Theorie, die Konvergenz des angewendeten Verfahrens garantieren sollte. Eine Lösung sollte klar erkennbar sein: Ich suche Geodäten zwischen Kurven. Start- und Endkurve sollten also nahe bei meinen zwei vorgegebenen Kurven sein. Das tun sie im Moment nicht - das wundert mich aber nicht allzusehr, da die Zahl der Punkte, an denen ich die Kurven auswerte, mindestens ein paar hundert groß sein muss, bevor ich Konvergenz erwarten kann...
Die Zeitdiskretisierung wird von dem Verfahren geliefert, das ich für meine Arbeit verwenden sollte. Das Verfahren funktioniert auch (ich habe es für Schalenmodelle gesehen, das muss einfach auch für Kurven klappen), allerdings soll es ein wenig bockig sein. Keine Ahnung, was mir meine Kollegen damit sagen wollten.
Und NEIN!, ich implementiere das nicht von Hand. Sehr zum Missfallen meines Betreuers. Wahrscheinlich ein weiterer Abzug bei der Benotung, fürchte ich.
Ich habe auch schon die Startwerte radikal variiert - mein erster Ansatz läuft bisher immer am Längsten. Alle anderen gehen völlig den Bach runter und konvergieren oft gar nicht.
*FRUST*
Warum habe ich eigentlich immer so störrische Diplomarbeiten in Gebieten, die ich kaum kenne?
I find your lack of faith disturbing.
|
|
|
|
|
|
|
|
|
|
|
Ist etwas ätzend zu lesen. Leider kommt auch keiner der Texte wirklich auf den technischen Kern der Geschichte. Ich verstehe immernoch nicht, was die cancellations jetzt zu bedeuten haben und wieso genau die künstliche Latenz das ganze Szenario denn jetzt besiegt.
Der NYTimes-Text erklärt das so:
Schritt 1: Unterschiedliche Latenzen ermöglichen front running.
Schritt 2: Börse mit künstlich hoher Latenz aufbauen
Schritt 3: ???????
Schritt 4: Alles gut.
|
|
[Dieser Beitrag wurde 3 mal editiert; zum letzten Mal von Rufus am 19.07.2014 2:24]
|
|
|
|
|
|
|
|
|
|
@WoS: Schonmal Newton-AMG oder Full Approximation Scheme ausprobiert?
|
|
|
|
|
|
|
|
|
|
|
Newton-AMG sagt mir gar nichts und mit Google finde ich auch nichts.  Die Mehrgittergeschichte habe ich angefangen, aber sonderlich weit bin ich noch nicht gekommen. Mein erster Test war, Lösungen mit großer Gitterweite als Startwerte für feinere Gitter zu verwenden - das machte das Problem nur schlimmer... Und eigentlich dachte ich, das wäre gerade der Gedanke von Mehrgitterverfahren? Die Mehrgittergeschichte habe ich angefangen, aber sonderlich weit bin ich noch nicht gekommen. Mein erster Test war, Lösungen mit großer Gitterweite als Startwerte für feinere Gitter zu verwenden - das machte das Problem nur schlimmer... Und eigentlich dachte ich, das wäre gerade der Gedanke von Mehrgitterverfahren?
An der Zeitdiskretisierung kann ich nicht drehen - das ist eben Teil des Algorithmus', den ich in der Arbeit beharken soll.
Thou hast undone our mother. - Villain, I have done thy mother.
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von Wraith of Seth
Newton-AMG sagt mir gar nichts und mit Google finde ich auch nichts. Die Mehrgittergeschichte habe ich angefangen, aber sonderlich weit bin ich noch nicht gekommen. Mein erster Test war, Lösungen mit großer Gitterweite als Startwerte für feinere Gitter zu verwenden - das machte das Problem nur schlimmer... Und eigentlich dachte ich, das wäre gerade der Gedanke von Mehrgitterverfahren?
An der Zeitdiskretisierung kann ich nicht drehen - das ist eben Teil des Algorithmus', den ich in der Arbeit beharken soll.
Thou hast undone our mother. - Villain, I have done thy mother.
| |
Naja du willst den Fehler auf dem gröberen Gitter darstellen, nicht die Lösung.
Newton AMG ist halt einfach ein Newton-Verfahren, bei dem du das lineare Gleichungssystem mit einem algebraischen-Mehrgitter-verfahen löst. Lad dir mal Hypre und benutzt da den BoomerAMG.
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von Rufus
Ist etwas ätzend zu lesen. Leider kommt auch keiner der Texte wirklich auf den technischen Kern der Geschichte. Ich verstehe immernoch nicht, was die cancellations jetzt zu bedeuten haben und wieso genau die künstliche Latenz das ganze Szenario denn jetzt besiegt.
Der NYTimes-Text erklärt das so:
Schritt 1: Unterschiedliche Latenzen ermöglichen front running.
Schritt 2: Börse mit künstlich hoher Latenz aufbauen
Schritt 3: ???????
Schritt 4: Alles gut.
| |
Jemand bietet bestimmte Aktien (shares) zum Verkauf; andere setzen daraufhin Bestellungen ab (orders). Bevor nun aber die orders ausgeführt werden, wird ein Großteil der angebotenen Aktien wieder zurückgezogen (cancellations), so dass die orders so gut wie nie vollständig erfüllt werden können.
Hab ich das soweit verstanden?
Mein Problem: Wie wird damit Geld verdient? Wird durch das vorgegaukelte Aktienangebot und die darauf anspringenden Käufer der Preis künstlich erhöht? Und bevor man alle Aktien (sofern sie denn wirklich existieren) zum aktuellen niedrigen Preis verkauft, zieht man sie wieder zurück und bietet sie dann wieder zum nun erhöhten Preis an? Funktioniert das so?
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von horscht(i)
ndere setzen daraufhin Bestellungen ab (orders). Bevor nun aber die orders ausgeführt werden, wird ein Großteil der angebotenen Aktien wieder zurückgezogen (cancellations), so dass die orders so gut wie nie vollständig erfüllt werden können.
Hab ich das soweit verstanden?
| |
Das ergibt irgendwie keinen Sinn, weil ja, niemand hätte was davon. [siehe edit: Der Verkäufer hätte halt die Information, dass Bedarf an seinen Aktien besteht, fertig. Das ist wie ein Autoverkäufer, der ein Angebot ablehnt und es 10% teurer wieder aufstellt. Irgendwie ist das nicht zielführend im Sinne von Einnahmen.]
Das Ding worum es bisher geht ist ja:
- es gibt 500 p0t-Aktien zu 10€
- 300 davon liegen bei POTX und 200 bei LOLZX
- ich will *alle* (der Einfachheit halber) zu 10€ kaufen
- meine Order kommt bei POTX an, ich kriege die 300 von dort und die restlichen 200 müssen ja von LOLZX kommen, dorthin ist mein Auftrag aber derzeit noch unterwegs
(- der Preis steigt bei POTX)
- jemand bekommt meinen Kauf bei POTX mit und sieht, dass der Rest meiner Order auf dem Weg zu LOLZX ist, wohin der jemand aber schneller kommt als mein Teilauftrag
- der jemand kauft dort schnell x p0t-Aktien bevor mein Teilauftrag dort ankommt
--> mein Auftrag kommt schließlich an, aber es gibt seit wenigen Sekundenbruchteilen keine 200 Aktien zu 10€ mehr
- ich gucke dumm aus der Wäsche und schreibe einen NYT-Artikel
Hier liegt der Vorteil für den Schattenkäufer direkt auf der Hand: Er kaufte Aktien, die unmittelbar danach im Wert gestiegen sind (durch meinen POTX-Kauf)
Und in diesem Szenario bewegen sich meine zwei Fragen:
- wo kommen Cancellations ins Spiel?
- warum würde das Problem gelöst, wenn POTX ne künstliche hohe Latenz implementiert?
// edit: ich verstehe deinen Ansatz aber auch, nur ist das imho ein gänzlich andere Szenario. Dafür müsste ja ein böswilliger Verkäufer beteiligt sein. Davon ist aber in den Texten nirgends die Rede. Es scheint um gutwillige Verkäufer und Exchanges zu gehen, sowie dich und einen weiteren kaufenden Akteur.
|
|
[Dieser Beitrag wurde 12 mal editiert; zum letzten Mal von Rufus am 19.07.2014 19:40]
|
|
|
|
|
|
| Thema: pOT-lnformatik, Mathematik, Physik XVI ( Ship painting activities ) |








![AUP [smith] 29.07.2010](./avatare/upload/U1066026--zeratul.png)














