|
|
|
|
|
|
|
Ich habe p0tbezug vermisst.... 
Ansonsten. GZ! 
|
|
|
|
|
|
|
|
|
|
|
Blauer Desktop Hintergrund, KDE 3.5? Ich glaube, du hast dich schon genug selbst geröstet!

|
|
|
|
|
|
|
|
|
|
|
Das ist der Kontrollraum vom Mikroskop, da sitze ich sowieso nie. Ist rein kosmetisch, dass die mich da filmen wollten.
Ich habe natürlich, wie es sich geziemt, den i3wm.
|
|
|
|
|
|
|
|
|
|
|
Hatte auch eine Weile Tiling Window Manager, aber viele GUI zentrische Programme sind damit eher nervig. Aber Plasma5 kann natürlich auch die Fenster in Tiles aufteilen (Ich mach meist 100%, 50%, oder 25%.
|
|
|
|
|
|
|
|
|
|
|
|
Der Fehler liegt bei GUI zentrisch.
|
|
|
|
|
|
|
|
|
|
|
Meistens, ja
|
|
|
|
|
|
|
|
|
|
|
Timestamp 0:42. Stop. Enhance! Das doch ne Rubberdome!
Timestamp 2:15. Enhance! Das doch Windows XP im Bild!
3:25 - IntelliJ. Guter Mann.
Coole Idee die Animation aus dem Film gleichzeitig im "Interview" auf dem Bildschirm in Blender offen zu haben.
|
|
|
|
|
|
|
|
|
|
|
|
Wie gerne ich so 1 stabiler Dude wäre
|
|
|
|
|
|
|
|
|
 halbe Haare zum halben Preis
halbe Haare zum halben Preis
|
- 0:17 - "quantitatively" spricht man wohl etwas anders betont aus, oder? 
- 1:55 - "resolutions much, much smaller"? nicht higher/finer?
- ...
- PROFIT!
Schön und auch für fach-fremde verständlich. Gefällt 
|
|
|
|
|
|
|
|
|
|
|
Ja das mit der resolution ist peinlich, aber quantitatively würde ich so aussprechen.
Anyway, das roast me war eigentlich nicht ernst gemeint. Ich hasse es, mich zu sehen und zu hören. Ihr wollt nicht wissen, wie viele takes ich gebraucht habe weil ich so nervös war.
|
|
|
|
|
|
|
|
|
|
|
Es ist auf jeden Fall um Welten besser als alles, was ich vor mich hin gestammelt bekommen hätte 
|
|
|
|
|
|
|
|
|
|
|
Ich (amerikanisches Englisch) würde das A kurz machen. Aber Amerikaner haben auch keine Ahnung von Englisch, daher...
Die Youtubeamerikanerin macht das auch.
Ich traue keinem englischen Wort obwohl ich englischsprachig aufgewachsen bin. Grain of salt und so.
|
|
[Dieser Beitrag wurde 2 mal editiert; zum letzten Mal von SwissBushIndian am 19.12.2018 21:09]
|
|
|
|
|
|
|
|
|
| | Zitat von Oli
Anyway, das roast me war eigentlich nicht ernst gemeint. Ich hasse es, mich zu sehen und zu hören. Ihr wollt nicht wissen, wie viele takes ich gebraucht habe weil ich so nervös war.
| |
I feel you.
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von Oli
Oh, und, Wissenschaftler--; industriemalocher++.
| |
Gratuliere!
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von SwissBushIndian
Ich (amerikanisches Englisch) würde das A kurz machen. Aber Amerikaner haben auch keine Ahnung von Englisch, daher...
Die Youtubeamerikanerin macht das auch.
Ich traue keinem englischen Wort obwohl ich englischsprachig aufgewachsen bin. Grain of salt und so.
| |
Tatsache. Das habe ich Jahre lang falsch pronounced. Dang!
/e: doch nicht, American English is langes A: https://dictionary.cambridge.org/pronunciation/english/quantitative
Credibility wieder hergestellt.
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Oli am 19.12.2018 21:27]
|
|
|
|
|
|
|
|
|
Genau das meine ich. Also stimmt das wohl nur bedingt und in Chicago ist das A auch kurz.
Kacksprache. Wie immer.
|
|
|
|
|
|
|
|
|
|
|
|
Stabiles Video, stabiler Typ. 5/7
|
|
|
|
|
|
|
|
|
|
|
Ich greife nochmal meine xml Frage von vor ein paar Seiten auf:
Gibt es einen geeigneten Datentyp um in Python einen tabellenförmigen Output zu erzeugen?
Jede Zeile soll einer ID entsprechen, für jede ID hole ich mir die benötigten Informationen per XPath aus dem jeweiligen Baum, im folgenden nenne ich das (inkorrekterweise?) Query. Ganz naiv konkateniere ich die Ergebnisse, also die erste Zeile im File (Header der Tabelle) ist
| |
| Code: |
"Path/to/ID" + "," + "Query1" + "," + "Query2" + "," + ... |
|
und die darauffolgenden Zeilen dann
| |
| Code: |
ID1 + , + [Result Query 1 für ID1] + , + [Result Query 2 für ID1] + , + ...
ID2 + , + [Result Query 1 für ID2] + , + [Result Query 2 für ID2] + , + ... |
|
Das funktioniert soweit für Queries mit 0-1 Ergebnissen, in Zukunft werden da aber auch Queries mit unbekannter Anzahl (>1) Ergebnissen dazukommen.
Könnte man jetzt händisch hinbasteln, Maximum der Ergebnisse für jeden Query merken, Tabelle entsprechend verbreitern, bei IDs mit weniger Resultaten mit Leerfeldern auffüllen etc - aber das geht doch bestimmt besser?
|
|
|
|
|
|
|
|
|
|
|
Also das sieht ja stark nach csv aus.
|
|
|
|
|
|
|
|
|
|
|
Ich würde die Tabelle grundsätzlich als Array initialisieren. Anstatt also jede Zeile als String zusammenzubauen, hast du eine Null-Matrix mit der Dimension n*m, wobei n die Anzahl der IDs ist, und m die höchste Anzahl an Ergebnissen.
// n muss natürlich gar nicht fix bekannt sein. Beim zusammenstellen der Ergebnisse kann die Länge der Tabelle beliebig wachsen. Nur die maximale Breite musst du irgendwie wissen - es sei denn, da gibt es in Python was eleganteres, aber da kenn ich mich damit zu wenig aus.
Um m zu ermitteln, muss man initial mal über alle Daten iterieren, was halt etwas kacke ist. Je nachdem, um wie viele Daten es geht, kann das aber schon OK sein. Vielleicht gibt es noch eine andere Logik, um m zu ermitteln ohne über alles drübergucken zu müssen (z.B. geschickter Query nach einer Kennzahl im Dokument?)
Dann kannst du nach belieben die Zellen der Zeile mit Ergebnissen befüllen. Da wo nix drin stehen soll, bleibt die Zelle leer.
Im Anschluss gibt es sicher x Tools um mit Python das ganze in ein Ausgabedokument wie CSV zu verwandeln.
|
|
[Dieser Beitrag wurde 2 mal editiert; zum letzten Mal von derSenner am 02.01.2019 19:31]
|
|
|
|
|
|
|
|
|
Das Inputfile ist halt sehr groß, da will ich auf jeden Fall vermeiden mehr als einmal drüber zu gehen. Ich kann mein Ergebnis natürlich auch so zwischenspeichern
| |
| Code: |
[["ID", "Query1", "Query2", ...],
[ID1, [Query1], [Query2], ...],
[ID2, [Query1.1, Query1.2], [Query2], ...]] |
|
und dann anschließend die Tabelle nach Anzahl der Listeneinträge (hier gibt es bei ID2 zwei für Query1) verbreitern. Wird aber im Grunde zur gleichen Bastellösung wie oben angedeutet, jetzt steht das Maximum halt Implizit durch die Anzahl der Einträge. Dein Edit bringt meine Frage aber ganz gut auf den Punkt.
| | Zitat von derSenner
// n muss natürlich gar nicht fix bekannt sein. Beim zusammenstellen der Ergebnisse kann die Länge der Tabelle beliebig wachsen. Nur die maximale Breite musst du irgendwie wissen - es sei denn, da gibt es in Python was eleganteres, aber da kenn ich mich damit zu wenig aus.
| |
In der CSV Library sehe ich jetzt nichts so wirklich nützliches, außer halt der Schreibfunktion (ich packe auch nicht wirklich von Hand ein "," zwischen jeden Query, dafür sind es zu viele). DictWriter geht in die richtige Richtung, nur würde ich halt sowas wie
| |
| Code: |
Query1: [[ID1, Query1],
[ID2, Query1.1, Query 1.2],
[ID3],
[ID4, Query1.1, Query1.2, Query1.3]] |
|
(Beispiel mit 1,2,0,3 Ergebnissen) erzeugen und Key sowie Anzahl Values auf Spalten mappen wollen, nicht Keys auf Zeilen wie es csv.dictwriter macht.
|
|
|
|
|
|
|
|
|
|
|
Liste von Tupeln, dem CSV-Writer ist egal wieviel du da reinsteckst, solange es konsistent ist.
AKA ich versteh nicht ganz das Problem was du hast/siehst
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von csde_rats am 02.01.2019 23:52]
|
|
|
|
|
|
|
|
|
|
Wenn du ohnehin mit XML arbeitest - warum gibst du nicht XML aus? Dann musst du nicht das Dateiformat aus der Hölle benutzen und die Leute die deine Daten mal weiterverwenden wollen müssen nichts neues parsen. Und dein Problem stellt sich garnicht erst, weil du kein flatten machen musst, sondern einfach die Listen ausgeben kannst.
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von B0rG* am 03.01.2019 1:06]
|
|
|
|
|
|
|
|
|
|
Als ob XML weniger Hölle als CSV wäre. Ich nehme mal an, dass das XML wenig geordnete Daten hat, und das resultierende CSV erst die relevanten Daten sammelt.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ich understande nicht, was das für einen Vorteil hat, eine simple Datenliste als XML auszugeben, das meine ich. Wenn überhaupt würde mich das mehr nerven.
Irdorath müsste halt mal definieren, wie das Ausgabefile aussehen soll. Tabelle mit Lücken in den Zellen wo keine Werte sind? Tabelle mit Werten einfach aneinandergereiht? Weil so ganz versteh ich das nicht.
|
|
[Dieser Beitrag wurde 4 mal editiert; zum letzten Mal von derSenner am 03.01.2019 1:17]
|
|
|
|
|
|
|
|
|
Nun, ich habe oben zwei Vorteile beschrieben: Den der Konsistenz mit den vorhandenen Daten und den der Tatsache, dass das Dateiformat anscheinend besser zu den Daten passt, da es kein Flachklopfen erfordert.
Sollte die Konsistenz keine Rolle spielen (und ich würde mir eine Minute Zeit nehmen darüber nachzudenken), dann wäre immernoch sowas wie YAML besser als CSV aufgrund des zweiten Arguments.
e/ Ein Vorschlag zur Güte: Wenn schon CSV, dann bitte Tidy data, da stellt sich das Problem auch nicht.
|
|
[Dieser Beitrag wurde 2 mal editiert; zum letzten Mal von B0rG* am 03.01.2019 1:23]
|
|
|
|
|
|
|
|
|
Kennt hier jemand gute Literatur zu Eventstudien in R? Wenn ich danach google lande ich immer nur auf fertigen Packages für R.
Ich habe Aktienkurse der letzten fünf Jahre und möchte dort die Auswirkungen eines Events pro Jahr betrachten.
|
|
|
|
|
|
|
|
|
|
|
Hallo , es ist mir ein wenig peinlich aber kann mir jemand bei dieser Aufgabe helfen ?
Soweit berechnen , wie möglich . Das ich erstmal alles auf einen Nenner bringen muß , ist mir klar . Nur , wie geht es dann weiter?
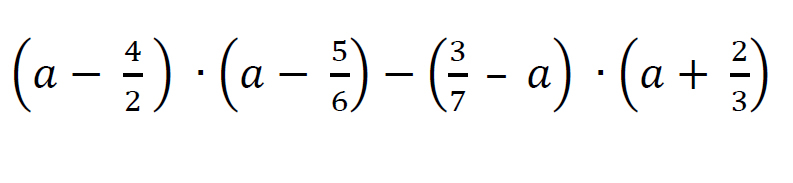
|
|
|
|
|
|
|
|
|
|
|
Munteres Raten? Bin ich bei!
Spoiler - markieren, um zu lesen:
Krass wie man so Zeug vergisst, oder?
Ich wuerde einfach die Klammern ausmultiplizieren. Das gibt ne quadratische Gleichung, die kannst du dann ggf mit p/q-Formel oder sonstwie aufloesen afair
bei mir kam auf die Schnelle a^2 - (387/252)a + 174/252 raus - das ist echt zu lange her ...
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Flitzpiepe42 am 04.01.2019 10:06]
|
|
|
|
|
|
| Thema: pOT-lnformatik, Mathematik, Physik XXII ( Jetzt nehmen uns Computer schon die Memes weg! ) |

















