|
|
|
|
|
|
Python / PANDAS
|
Ich habe diverse Listen, die ich mit PANDAS beackern mag. Basis ist eine relative lange Liste mit diveren Spalten, von denen eine Duplikate enthält.
| SpalteA | SpalteB | SpalteC | ... | SpalteX | | | xxx | 12 | beschreibung1 | ... | andere Daten | | | xxy | 5 | beschreibung2 | ... | andere Daten | | | xxz | 9 | beschreibung3 | ... | andere Daten | | | ... | ... | ... | ... | ... | | | xxx | 15 | beschreibung1 | ... | andere Daten | |
Daraus mag ich eine neue Liste basteln, in der nur die eindeutigen Werte aus Spalte A enthalten sind, keine Duplikate. Über SpalteB wird summiert Unser Beispiel würde also eine Zeile weniger enthalten.
| SpalteA | SpalteB | SpalteC | ... | SpalteX | | | xxx | 27 | beschreibung1 | ... | andere Daten | | | xxy | 5 | beschreibung2 | ... | andere Daten | | | xxz | 9 | beschreibung3 | ... | andere Daten | | | ... | ... | ... | ... | ... | |
Für die übrigen Daten gelten 1:1 Beziehungen, z.B. hat "xxx" immer "beschreibung1" und die will ich schlicht "hinten dran" klatschen. Teilweise sind noch Daten Spalten aus anderen Excels zu ergänzen (können, müssen aber nicht alle Einträge aus Spalte A enthalten).
Im Prinzip will ich klassische SVERWEIS Gymnastik aus Excel geschickt umgehen.
Ich bekomme das sicher hin, aber vielleicht hat jemand einen eleganten Weg, da es doch recht viele Spalten/Daten sind?
|
|
|
|
|
|
|
|
|
|
|
Das klingt doch nach Standard group by und aggregate in SQL. Da hat pandas doch sicher was Ähnliches zu bieten.

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Oh, groupby hat eine Summenfunktion...lalalala.
Danke schonmal!
|
|
|
|
|
|
|
|
|
|
|
Nochmal ne Anfängerfrage:
Lerne grade python fürs Studium - bin aber noch ganz am Anfang.
In dem Buch gibt es jetzt so ein "Kopfrechenspiel" zu programmieren. Und im großen und ganzen verstehe ich das auch alles. Habe es so nachgebaut wie im Buch beschrieben, aber 1-2 Kleinigkeiten sind mir nicht ganz schlüssig...
| |
| Code: |
#Zufallsgenerator
import random
random.seed()
#Aufgabe
def aufgabe():
a = random.randint(1,10)
b = random.randint(1,10)
erg = a + b
print ("Die Aufgabe: ", a, "+",b)
return erg
#Kommentar
def kommentar(eingabezahl, ergebnis):
if eingabezahl == ergebnis:
print(eingabezahl, "ist richtig")
else:
print(eingabezahl, "ist falsch :(")
#Aufgabe
c = aufgabe()
#Schleife und Anzahl initialisieren
zahl = c + 1
versuch = 0
#while Schleife
while zahl != c:
#Anzahl Versuche
versuch = versuch + 1
#Eingabe
print("Bitte Zahl eingeben")
z = input()
#Versuch einer Umwandlung
try:
zahl = int(z)
except:
#Falls Umwandlung nicht erfolgreich
print("Sie haben keine Zahl eingegeben")
#Schleife fortsetzen
continue
#kommentar
kommentar(zahl,c)
#Anzahl Versuche
print("Ergebnis: ",c)
print("Anzahl Versuche: ",versuch) |
|
1. Frage: Bei dem zweiten "#Aufgabe" wird die Funktion durch c = aufgabe() aufgerufen. Mir erschließt sich aber nicht warum. Habe es versucht direkt nur mit "aufgabe()" zu starten und dann bei der Zeile darunter "zahl = erg + 1" zu setzen, das gibt aber nen Fehler, weil "erg" angeblich nicht definiert ist (sollte es doch aber eigentlich?)
2.Frage: das "continue" bei dem except soll doch grundsätzlich bewirken, dass die schleife forgesetzt wird. Ist das nicht aber unnötig, da die while-Schleife doch nach wie vor aktiv ist? Zumindest funktioniert der code auch ohne das "continue" - oder sollte ich mir das einfach gleich angewöhnen weil es generell sinnvoll ist?
|
|
|
|
|
|
|
|
|
|
|
Ich geb dir erstmal ein paar Pointer. Glaube das hilft für das Verständnis mehr als eine komplette Lösung.
| | Zitat von Apache
1. Frage: Bei dem zweiten "#Aufgabe" wird die Funktion durch c = aufgabe() aufgerufen. Mir erschließt sich aber nicht warum. Habe es versucht direkt nur mit "aufgabe()" zu starten und dann bei der Zeile darunter "zahl = erg + 1" zu setzen, das gibt aber nen Fehler, weil "erg" angeblich nicht definiert ist (sollte es doch aber eigentlich?)
| |
https://matthew-brett.github.io/teaching/global_scope.html
| |
2.Frage: das "continue" bei dem except soll doch grundsätzlich bewirken, dass die schleife forgesetzt wird. Ist das nicht aber unnötig, da die while-Schleife doch nach wie vor aktiv ist? Zumindest funktioniert der code auch ohne das "continue" - oder sollte ich mir das einfach gleich angewöhnen weil es generell sinnvoll ist?
| |
Hast du schon mal passiert, ob das gleiche passiert, wenn du das `continue` rausnimmst und direkt bei der ersten Nachfrage Enter drückst? Zweitens: Was ist der Output, wenn du erst eine Zahl eingibst und beim zweiten Mal nicht? Ist das ein gewünschter Output?
|
|
|
|
|
|
|
|
|
|
|
Ah verstehe, also Punkt1  Vielen Dank dafür! Vielen Dank dafür!
Bei der zweiten Frage aber nicht so ganz, es klappt alles auch ohne continue, egal was ich eintippe (ich rede nur von dem continue Befehl - nicht vom try/except)
|
|
|
|
|
|
|
|
|
|
|
|
Was heißt es klappt - vergleich mal den Output mit und ohne `continue`-Zeile für Zeile. Wenn du den Unterschied gefunden hast, starte das Programm und mach das Experiment noch mal. Fällt etwas auf? Wenn nicht, kopier gerne mal den Output mit und ohne hier rein.
|
|
|
|
|
|
|
|
|
|
|
nvm  danke, habe gesehen worauf du hinauswillt danke, habe gesehen worauf du hinauswillt 
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Apache am 12.02.2021 21:18]
|
|
|
|
|
|
|

|
Unterschreibt ihr das:
Die Herstellung einer Mittelwertfreiheit des Ursprungssignals wäre in einer diskreten Fouriertransformation äquivalent zu einem nachträglichen Verwerfen des ersten Fourierkoeffizienten.
|
|
|
|
|
|
|
|
|

|
|
Keine Ahnung, aber wie writest du?
|
|
|
|
|
|
|
|
|

|
|
Danke, Irdo. Wirklich. Vielen, herzlichen Dank.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Geil, ein "ja" vom Signalmessias des pOTs - das reicht mir. Thx rats <3
|
|
|
|
|
|
|
|
|
|
|
Musste erstmal googlen, was mittelwertfrei ist. Deutsch Mutterficker, sprech ich es?
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Der Satz ist schon Aneurysma auslösend schwurbelig. Teilweise ist das Büßers Schuld
(wäre äquivalent -> entspricht)
und teilweise des Faches
(Herstellung einer Mittelwertfreiheit des Ursprungssignals -> Das Ursprungssignal zentrieren).
Verpflichtende Kommunikationskurse für Stemlords, damit ziehe ich in den Bundestag ein!
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Irdorath am 14.02.2021 8:51]
|
|
|
|
|
|
|
|
|
|
Die Endfassung ist ein bisschen unschwurbeliger!
|
|
|
|
|
|
|
|
|
|
|
Mich nervt gerade die blöde TableView von JavaFX. Oder eher meine mangelnde Erfahrung... Aus irgendwelchen Gründen bekomm ich drei Spalten der Tabelle nicht bestückt. Alle anderen gehen. Die Daten dafür hol ich aus einer List mit Objekten, aber da geht schon was schief. Eine der drei Spalten soll mit einem Boolean gefüllt werden, der ist aber a) immer false und b) taucht er wie erwähnt nicht in der Tabelle auf... 
/edit: gelöst...
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von ]N-Squad[Crow am 19.02.2021 21:37]
|
|
|
|
|
|
|
|
|
Und nochmal Python / Pandas.
Wie kann ich ein Dataframe mit multi-indizierten Spalten und ein Dataframe mit einzel-indizierten Spalten mergen, joinen etc. Die Zeilenindizes der Dataframes sind identisch.
Man kann das einfach machen, aber dann wird der Multi-Index zu einem Einzelindex zusammengestaucht. Außerdem gibt es eine Warnung.
Mir fällt bisher nur ein, den Multi-Index erstmal zu plätten und später wieder herzustellen. Das erscheint mir aber nicht sehr "pythonesque".
Hat da jemand was parat?
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von horscht(i) am 20.02.2021 14:29]
|
|
|
|
|
|
|
|
|
Unter Ubuntu compilen.
Ich brauch mal Nachhilfe. Ich möchte dieses Tool unter ubuntu benutzen:
https://gitlab.com/jas/pmccabe
Beim Versuch das Ding auszuführen erhalte ich jedoch
"cannot execute binary file: exec format error"
Laut Google liegt das an Inkompatibilität 32/64 Bit Architektur. Kann ich einfach im Makefile sagen "mach 64 bit lan!"? Wenn ja, wie?
|
|
|
|
|
|
|
|
|
|
|
Hm. Ich kann auf meiner Kiste ein simples "make" in die Kommandozeile schmeißen und es spuckt 64bit binaries aus. Prinzipiell solltest du vorher build-essentials installieren.
sudo apt install build-essential
Wie kompilierst du denn und was genau versuchst du dann auszuführen?
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von statixx am 24.02.2021 11:09]
|
|
|
|
|
|
|
|
|
|
Gibt auch ein AUR Paket. Das kannst du zwar unter Ubuntu nicht direkt verwenden (falscher Paketmanager), aber du kannst sehen was gemacht werden muss zum Kompilieren. Und die Antwort ist - wie statixx sagt - eigentlich nichts besonderes außer make.
|
|
|
|
|
|
|
|
|
|
|
Auch ganz normal per "make" im Verzeichnis. Kriege aber einige Warnungen:
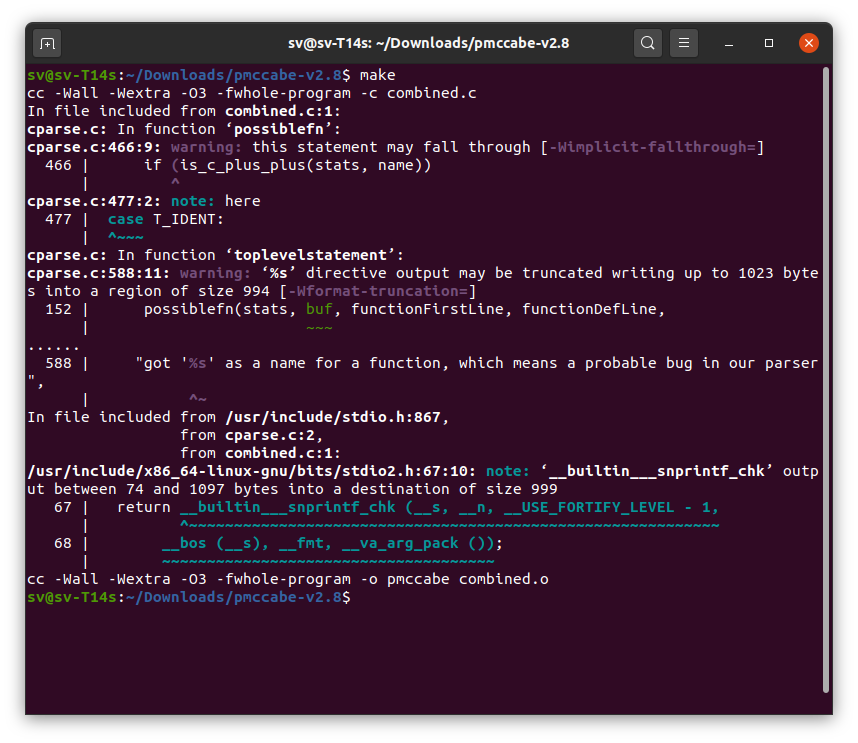
build-essential habe ich installiert, brachte leider keine Änderung.
/e: Wie man sieht habe ich v2.8 heruntergeladen und nicht den "master". Macht das vllt einen Unterschied?
/e²: Weils leider auf dem Screenshot nicht zu sehen ist:
| |
| Code: |
chmod u+x combined.o
./combined.o
|
|
Habe nach dem Kompilieren versucht. Und da scheint wohl der Fehler zu liegen /o\ ich will ./pmccabe vermutlich
|
|
[Dieser Beitrag wurde 2 mal editiert; zum letzten Mal von Swot am 24.02.2021 11:32]
|
|
|
|
|
|
|
|
|
So sieht das bei mir auch aus. Danach fällt folgende Binary raus:
~/pmccabe master ❯ file pmccabe
pmccabe: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=6e3866ce8bf1155f70cc1993ce29c824cdced094, for GNU/Linux 3.2.0, not stripped
Wie sieht das bei dir denn dann aus?
/e: Ah. combined.o ist nur ein object-file, kein executable. Versuch mal ./pmccabe auszuführen, das sollte gehen.
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von statixx am 24.02.2021 11:35]
|
|
|
|
|
|
|
|
|
Daran lag es. Ist bei mir schon wieder eine Weile her  Danke dir. Danke dir.
/e: Übrigens gibts das Ding auch als Package.. ein einfaches sudo apt install pmccabe wäre auch gegangen 
|
|
[Dieser Beitrag wurde 2 mal editiert; zum letzten Mal von Swot am 24.02.2021 12:55]
|
|
|
|
|
|
|
|
|
Jetbrains feiert gerade 20 Jahre IntelliJ. Passen dazu gibt es eine Konferenz. Gestreamt werden die Panels hier.
Und hier findet ihr die Panels.
Gleich geht es bspw. um den Debugger.
|
|
|
|
|
|
|
|
|
|
|
|
Werde ich mir die Tage mal in Ruhe anschauen. Finde ich aber super, dass Jetbrains da hinterher ist tutorial Videos zu machen und das sie nun beschlossen haben, eine eigene Conf sogar auszutragen.
|
|
|
|
|
|
|
|
|
|
|
Ich will (empirisch) zeigen, wie sich die Rechenzeit eines Pythonprogramms erhoeht, wenn ich die Anzahl der Inputs erhoehe.
Also das Programm nimmt als Input Parametersets
params1, params2, ..., paramsN
und berechnet damit etwas, ich will messen, was fuer wachsendes N passiert.
Das hab ich ganz naiv als Loop implementiert, also ich lasse das Programm M mal mit N=2 laufen, dann M mal mit N=3, dann M mal mit N=4, usw, und speicher mir die (durchschnittliche) Laufzeit fuer bestimmte Programmabschnitte (in Sekunden) ab.
Bloederweise passiert jetzt das folgende:
| |
| Code: |
Model params Joint calc Total: Method1 Total: Method2
N
2 0.860611 1.124352 1.984997 5.057610
3 0.107431 1.468007 1.575478 7.332437
4 0.115554 1.979398 2.094989 11.773657
5 0.132536 2.522544 2.655118 17.486578
|
|
Die Inputparameter muessen erst noch in Modellparameter umgerechnet werden, die Zeit dazu ist in der ersten Spalte.
Aus irgendeinem Grund, dauert das fuer die initiale Konfiguration wesentlich laenger, als fuer die darauffolgenden. Gut, jetzt wuerde ich denken, dass halt die aus params1, params2 berechneten Modellparameter gespeichert bleiben, und er nur noch eine zusaetzliche Berechnung fuer das neue params(N+1) macht.
Aber ich rechne ja auch schon fuer N=2 Parameter die M Durchgaenge, dann sollte er doch eigentlich nur im allerersten Durchgang eine hohe Rechenzeit haben, und in den restlichen M-1 Durchgaengen auch sehr schnell sein? Dem ist nicht so:
| |
| Code: |
array([0.8406213, 0.8481368, 0.8420234, 0.8602231, 0.8520199, 0.8710735,
0.8782366, 0.8779248, 0.854982 , 0.8808711]) |
|
Woran koennte das liegen, was kann ich tun? Die Durchgaenge werden alle identisch (in der gleichen Schleife) als Funktionsaufruf gestartet.
Wenn ich so rumgoogle, sollte man das wohl besser mit profiler oder timeit machen, aber das wuerde mich eingies an Zeit fuers Umschreiben des Codes kosten. Vielleicht gibt's ja nen easy fix fuer die naive Methode?
Die Variablendeklarationen mit in den Loop packen, und so ne hacky "clear all" Loesung davor?
e: Wenn ich mir die Zahlen fuer Method1 in der letzten Zeile genauer anschaue...

Wat?
Ich setze im Grunde Timestamps:
| |
| Code: |
t_init
(berechne Modellparameter)
t_param
(berechne joint calc)
t_joint
(berechnet Methode 1 spezifisches)
t_method1
=>
Parametrization time = t_param - t_init
Joint Calc time = t_joint - t_param
Total Method1 time = t_method1 - t_init
|
|
Wieso zum Teufel kommt da ne kuerzere Zeit raus, als fuer die Zwischenschritte. 
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Irdorath am 27.02.2021 11:22]
|
|
|
|
|
|
|
|
|
|
Eine Idee in die andere richtung: N=1 zweimal laufen lassen? Wenn dich nur die relation zwischen den Iterationen interessiert, könnte das auch reichen. Wieso N=1 länger dauert ist ne gute Frage, evtl optimiert der interpreter in den folgenden Durchläufen, bzw hat das im ersten Durchlauf erledigt. Wild guess.
|
|
|
|
|
|
|
|
| Thema: pOT-lnformatik, Mathematik, Physik XXIII |








![[Dicope]](./avatare/drkleiner.gif)



![AUP ]N-Squad[Crow 03.05.2013](./avatare/upload/U29244--bendercastiel_final_125px.png)


