|
|
|
|
|
|
|
Hach, vielen Dank! 
@Peace: Ich wurde aber zum Glück von zwei Personen entwickelt, die wussten, was sie taten. Und ich wurde auch besser gewartet. 
|
|
|
|
|
|
|
|
|
|
|
alles gute!
---
Ich bau gerade ne Priority Queue und nutze dazu nen ternaeren Heap. Die PQ soll in Dijkstra verwendet werden, was ich mich jetzt gerade frage, ist, wie man am Besten eine DecreasePriority() einbaut. Gibts da was effizienteres als im ganzen Heap nachzuschauen ob ein Wert schon vorhanden ist und dann die Prioritaet anzupassen? 
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von Renga
Ich bau gerade ne Priority Queue und nutze dazu nen ternaeren Heap. Die PQ soll in Dijkstra verwendet werden, was ich mich jetzt gerade frage, ist, wie man am Besten eine DecreasePriority() einbaut. Gibts da was effizienteres als im ganzen Heap nachzuschauen ob ein Wert schon vorhanden ist und dann die Prioritaet anzupassen?
| |
Hab das jetzt nicht alles im Kopf, aber müssen die einzelnen Tasks denn numerische Prioritäten haben? Oder reicht nicht deren Position innerhalb der Queue? Da du diese ja wahrscheinlich als verkettete Liste implementiert hast, könntest du ja auch Knoten tauschen.
Ich müsste mich da allerdings nochmal einlesen.
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von [DK]Peacemaker
| | Zitat von Renga
Ich bau gerade ne Priority Queue und nutze dazu nen ternaeren Heap. Die PQ soll in Dijkstra verwendet werden, was ich mich jetzt gerade frage, ist, wie man am Besten eine DecreasePriority() einbaut. Gibts da was effizienteres als im ganzen Heap nachzuschauen ob ein Wert schon vorhanden ist und dann die Prioritaet anzupassen?
| |
Hab das jetzt nicht alles im Kopf, aber müssen die einzelnen Tasks denn numerische Prioritäten haben? Oder reicht nicht deren Position innerhalb der Queue? Da du diese ja wahrscheinlich als verkettete Liste implementiert hast, könntest du ja auch Knoten tauschen.
Ich müsste mich da allerdings nochmal einlesen.
| |
Ich hab die Queue komplett als Heap implementiert, die Prioritaet spiegelt dann die Position im Heap (welcher die Queue repraesentiert) wieder.
Die Elemente liegen als record im Heap also:
| |
| Code: |
type PrioElement is record
Value : Integer;
Priority : Integer;
end record;
type Heap is array (Integer range <>) of PrioElement;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ich versteh das Problem nicht ganz
|
|
|
|
|
|
|
|
|
|
|
Oh ... hat sich erledigt, ich habs. 
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von Renga
Weil ich grade das hier lese:
Ehrlich gesagt hab ich ja auch einige Softwareprofile auf Dropbox gesichert
Einerseits ist fefe ein ueber paranoider Nerd, andererseits haette ich trotzdem kein Bock, dass jemand an Daten von mir drankommt, egal welche Relevanz die fuer mich haben.
Werds wohl alles verschluesseln oder nichtmehr dort "Backuppen".
| |
Wäre ja alles halb so schlimm, wenn Fefe nicht immer mit seiner "Ich hatte Recht und ihr seid alle Scheiße!"-Nummer daher käme. :/
|
|
|
|
|
|
|
|
|

|
|
Oh, to whom it may concern: alles Gute (nachtraeglich)!
|
|
|
|
|
|
|
|
|
|
|
|
Alles Gute nachträglich cmx.
|
|
|
|
|
|
|
|
|
|
|

Nö. Wuala ftw.
|
|
|
|
|
|
|
|
|
|
|
Hmpf, ich muss einkaufen gehen. Kein Kaffee mehr 
|
|
|
|
|
|
|
|
|
|
|
|
Ich bin wieder da-ha!
|
|
|
|
|
|
|
|
|
|
|
Danke, restlicher Salat.
Alles gute noch, CMS.
|
|
|
|
|
|
|
|
|
|
|
Glückwunsch cms!
Letztes (?) Übungsblatt in Softwaretechnik: Den Floyd-Steinberg-Algorithmus so gut wie möglich parallelisieren. Die besten 3 bekommen je ein Buch über parallelisiertes Rechnen. Da bin ich doch dabei
|
|
|
|
|
|
|
|
|
|
|
Sollten das Buch nicht eher alle hinter Platz 3 kriegen? 
|
|
|
|
|
|
|
|
|
|
|
Der Vorschlag kam auch, woraufhin der Übungsleiter einen kleinen philosophischen Vortrag gehalten hat ob es sinnvoller ist Leistung zu belohnen oder die Schwächeren zu fördern. Vermutlich ist das eine Vorgabe die wir als Eliteuni haben dass nur die Besten die Preise bekommen
---
Wie ist die ideale Anzahl an Threads für so ein Programm? Seh ich das richtig dass mehr Threads als verfügbare Prozessorkerne keinen ernsthaften Geschwindigkeitsvorteil mehr bringen?
(edit: Ich sehe dass ich, wenn ich den Algorithmus so umbaue wie in dem gefundenen Paper, sowieso um einiges mehr Thread brauche. Also wohl egal)
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Danzelot am 22.06.2011 13:25]
|
|
|
|
|
|
|
|
|
| | Zitat von Danzelot
Glückwunsch cms!
Letztes (?) Übungsblatt in Softwaretechnik: Den Floyd-Steinberg-Algorithmus so gut wie möglich parallelisieren. Die besten 3 bekommen je ein Buch über parallelisiertes Rechnen. Da bin ich doch dabei
| |
Hast du ein funktionieres Programm? Hört sich nämlich interessant an.
|
|
|
|
|
|
|
|
|
|
|
|
Nein der Erste muss natürlich alle drei bekommen, wie sonst sollte er das Buch parallel lesen können?
|
|
|
|
|
|
|
|
|

|
|
Elite Uni ist so ein ekliges und asoziales Wort.
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von Danzelot
Wie ist die ideale Anzahl an Threads für so ein Programm? Seh ich das richtig dass mehr Threads als verfügbare Prozessorkerne keinen ernsthaften Geschwindigkeitsvortiel mehr bringen?
| |
Ja.
|
|
|
|
|
|
|
|
|
|
|
|
Vor allem frisst ja der Scheduler auch Rechenzeit.
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von [DK]Peacemaker
| | Zitat von Danzelot
Glückwunsch cms!
Letztes (?) Übungsblatt in Softwaretechnik: Den Floyd-Steinberg-Algorithmus so gut wie möglich parallelisieren. Die besten 3 bekommen je ein Buch über parallelisiertes Rechnen. Da bin ich doch dabei
| |
Hast du ein funktionieres Programm? Hört sich nämlich interessant an.
| |
Bisher habe ich nur dieses Paper. Ich habe ja auch erst heute morgen die Aufgabe erfahren
edit: Der Autor hat sich wohl noch ein paar Gedanken mehr gemacht und auch mal praktisch rumprobiert, dabei ist das hier rausgekommen.
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Danzelot am 22.06.2011 13:33]
|
|
|
|
|
|
|
|
|
Ich nehme ab an, dass ihr bei der FS-Matrix bleiben müsst, oder? Da das Paper ja (falls ich das richtig verstanden habe) eine andere Matrix anbietet, mir der sich das Quellbild diagonal partionieren lässt.
Meine erste Idee wäre ein Quadtree Partitionierung (damit man auf n-Kerne skalieren kann), bei fix 4 Threads würde es ausreichen das Bild in 4 Quadranten zu unterteilen.
Das übliche Divide also, das Conquer seh ich allerdings noch nicht parallel passieren, da die Randbereiche jedes Teilabschnitts ja nachbearbeitet werden müssen.
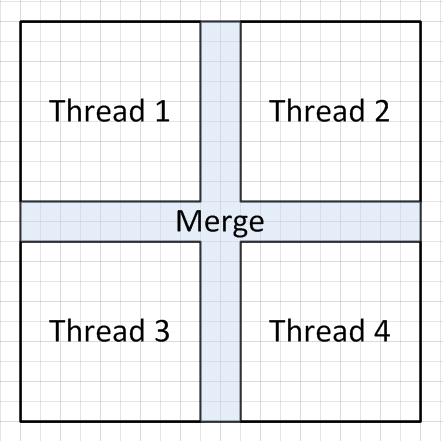
Gibt es Beschränkungen für den Speicher? Ich weiß nicht, wie das mit atomaren Operationen innerhalb von Java aussieht.
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von Danzelot
Glückwunsch cms!
Letztes (?) Übungsblatt in Softwaretechnik: Den Floyd-Steinberg-Algorithmus so gut wie möglich parallelisieren. Die besten 3 bekommen je ein Buch über parallelisiertes Rechnen. Da bin ich doch dabei
| |
So wie ich das gerade überblicke arbeitet das doch nur auf den jeweiligen Nachbarpixeln, oder? Da brauchst du doch das Orignalbild nur einlesen, in n Bereiche aufteilen und n Prozesse darauf loslassen. Das sollte man doch linear über die Prozessorkerne skalieren können
|
|
|
|
|
|
|
|
|
|
|
Das ist so nicht praktikabel, weil ein Pixel ja grundsätzlich von allen Pixeln oben/links abhängig ist - man muss also nicht nur die Randbereiche nacharbeiten sondern auch die Bereiche 2-4 sobald 1 abgeschlossen ist.
Mein eigener Ansatz wäre gewesen die Threads das Bild zeilenweise abarbeiten zu lassen und sie dann jeweils 2 Pixel verzögert zu starten. Das sähe dann so aus:

Der Ansatz in dem Paper die Threads diagonal arbeiten zu lassen ist, wenn ich das richtig verstehe, möglichst wenig Kommunikation zwischen den verschiedenen Kernen notwendig zu machen weil das so langsam ist.
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von Danzelot
Der Ansatz in dem Paper die Threads diagonal arbeiten zu lassen ist, wenn ich das richtig verstehe, möglichst wenig Kommunikation zwischen den verschiedenen Kernen notwendig zu machen weil das so langsam ist.
| |
Du machst das doch in Java, oder? Dann solltest du dir über sowas erstmal keine Gedanken machen
|
|
|
|
|
|
|
|
|
|
|
Es geht doch hier nicht über realistische Geschwindigkeiten, dann würde ich lernen wie man in Assembler parallelisiert
Die Frage ist wie man das möglichst cool umsetzt um das Buch zu bekommen
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
 Bei Firefox kann man Tabs mit Strg-Klick irgendwie markieren und dann ist ein (*) vor dem Titel. Aber da passiert nichts. Bei Firefox kann man Tabs mit Strg-Klick irgendwie markieren und dann ist ein (*) vor dem Titel. Aber da passiert nichts.
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von Danzelot
Es geht doch hier nicht über realistische Geschwindigkeiten, dann würde ich lernen wie man in Assembler parallelisiert
Die Frage ist wie man das möglichst cool umsetzt um das Buch zu bekommen
| |
Da es Java ist: Factories, Webservices und Dependency Injection!
|
|
|
|
|
|
|
|
| Thema: Gehirnsalat ( wir unter uns ) |






![[dk]peacemaker](./avatare/[dk]peacemaker.gif)











