|
|
|
|
|
|
|
Ich hoffe mal ihr deployt und konfiguriert das alles nicht von Hand. Das einzige was du dann bei Automation mit Replication hast ist die gleiche kaputte Konfiguration doppelt.
€: Und dein SSO Beispiel ist der Musterknabe von Erreichbarkeit. Wenn der einen Failover hat ist dein Dienst noch da und sonst hast du halt Pech gehabt.
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von SwissBushIndian am 31.03.2017 13:14]
|
|
|
|
|
|
|
|
|
In der Tat ist der von Hand zusammen geknöppelt worden. Bei der Software steht auch fett dran, dass die Standalone nur zu Testzwecken installiert werden soll, die Admins haben trotzdem entschieden, das Ding dann nur alleine laufen zu lassen. Ist ja halt durch die Hardware gesichert...
Ich docker mir das Ding als Cluster gerade lokal zusammen und das wird dann in unsere Build-Strecke integriert. Die Admins machen da meiner Meinung nach einen supoptimalen Job.
|
|
|
|
|
|
|
|
|
|
|
Ist noch jemand auf den Scaladays in Kopenhagen dieses Jahr? 
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Wie bestimmte ohne Taschenrechner ich bei einer komplexen Zahl (z.B. -1 + sqrt(3)i) den Winkel phi um die Zahl in Polar- oder Exponentialdarstellung ueberfuehren zu koennen? Ich brauche da ja ein arc-sin/tan/cos.
|
|
|
|
|
|
|
|
|
|
|
|
Mit einem Geodreieck?
|
|
|
|
|
|
|
|
|
|
|
Ich acker hier gerade ne alte Klausur durch zu der ich auch die Musterloesung vom Prof. habe.
Alle Loesungen der Gleichung x^6 + 1 = sqrt(3) * i.
Betrag ausrechnen ist ja easy. In der Musterloesung schreibt er dann einfach ohne jeglichen Rechenweg x^6 = 2 * e^(i*(2/3)*pi).
Hilft mir voll. 
|
|
|
|
|
|
|
|
|
|
|
Es gibt halt ein paar glatte Werte... so ist der Arctan von sqrt(3) = pi/3
(Ich hab heute noch Alpträume aus der Analysis 1 Klausur mit dem hilfreichen Hinweis des Dozenten: "Aktivieren Sie Ihr Wissen über Halbwinkelfunktionen!"...)
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von RichterSkala am 03.04.2017 20:19]
|
|
|
|
|
|
|
|
|
Die kann ich doch nicht alle auswendig kennen. Haette ich das mit dieser Tabelle hinbekommen muessen?
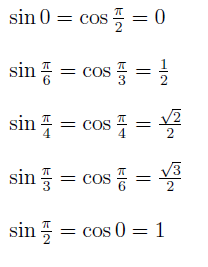
|
|
|
|
|
|
|
|
|

|
Ja, denn tan(pi/3)=sin(pi/3)/cos(pi/3)=(sqrt(3)/2) / (1/2) = sqrt(3).
Das giveaway ist die Wurzel 3, ähnlich wenn die Wurzel 2 in der Klausur auftauchen sollte, weißt du, welche Winkel schon mal im Spiel sein müssen. Ich finde sowas sau ätzend, aber Dozenten lieben diesen Scheiß.
|
|
[Dieser Beitrag wurde 2 mal editiert; zum letzten Mal von RichterSkala am 03.04.2017 20:27]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ich gucke mir meistens die dazugehörigen, rechtwinkligen Dreiecke lange an und das hilft meistens, um die entsprechenden Werte zu bekommen.
Ich fand so ein Gefudel eigentlich immer ganz unterhaltsam, genau wie mit gleichseitigen n-gonen komplexe Einheitswurzeln auszutüfteln...
Krawehl, krawehl! Taubtrüber Ginst am Musenhain, trübtauber Hain am Musenginst! Krawehl, krawehl!
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ich schäme mich fast, diese Frage zu stellen, aber ich komme jetzt einfach gerade nicht drauf, bzw. bin mir nicht sicher, ob ich etwas falsch verstehe oder ob nur schlampig gearbeitet wird. Es geht um Machine Learning und "anomaly detection". Zugrunde liegt mir die Normalverteilungsfunktion (Dichtefunktion).
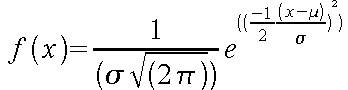
Ich habe m Trainingsdaten element R, alle unabhängig. p(x1,mu1, sigma1) ist die Normalverteilung (Dichte) von x1 mit Mittelwert mu1 und Standardabweichung sigma1. Nun wird p(x) als das Produkt der Dichtefunktionen mit den Trainingsdaten definiert, also
p(x) = p(x1,mu1,sigma1)*p(x2,mu2,sigma2)*...
Wenn dieses Produkt kleiner ist als Epsilon, dann liegt eine Anomalie vor.
So, nun verstehe ich die Logik, die zugrunde liegt. Ausreißer liegen an den Rändern der Dichtefunktion und haben einen Wert von beinahe 0. Aber hat dieses Produkt auch irgendeine mathematische Bedeutung? Die Dichtefunktion ist ja stetig und gibt keine (absolute) Wahrscheinlichkeit an. Es ist doch deshalb auch falsch, von "Wahrscheinlichkeit von x1/x2/x3..." zu sprechen, oder? Das Endprodukt gibt mir ja als solches dann auch keine Wahrscheinlichkeit an.
Hier ist noch ein Auszug aus dem Transkript:
| | | The way we are going to address anomaly detection, is we are going to model p(x) from the data sets. We're going to try to figure out what are high probability features, what are lower probability types of features. So, x is a vector and what we are going to do is model p of x, as probability of x1, that is of the first component of x, times the probability of x2, that is the probability of the second feature, times the probability of the third feature, and so on up to the probability of the final feature of Xn. | |
Danke für die Klarstellung. Das Ganze ist aus dem Machine-Learning-Kurs von Coursera. (https://www.coursera.org/learn/machine-learning/lecture/C8IJp/algorithm)
|
|
|
|
|
|
|
|
|
|
|
Den Kurs hab ich auch mal gemacht, wenn du weitere Fragen hast oder Lösungshilfen brauchst (hab alles ausser einer Übung (7?)), gerne.
Zur eigentlichen Frage: du schreibst, dass deine Zufallsvariablen unabhängig sind. Das heißt per definition, dass die Wahrscheinlichkeit der _gemeinsamen_ Verteilung faktorisiert:
p(x) = p(x1) * p(x2) * ...
Wobei x = (x1,x2,...)
|
|
[Dieser Beitrag wurde 2 mal editiert; zum letzten Mal von R am 04.04.2017 11:42]
|
|
|
|
|
|
|
|
|
Ja, das verstehe ich auch. Es macht auch wirklich Sinn für mich, das so zu machen.
Aber die (stetige) Dichtefunktion gibt ja keine Wahrscheinlichkeit an. Ich bin mehr von der Bezeichung verwirrt, dass f(x) die Wahrscheinlichkeit von x sein soll. Oder bin ich gerade einfach zu dumm? Weil bspw. mit geringem Sigma f(x)>1 ist, also stimmt das doch nicht ganz.
|
|
|
|
|
|
|
|
|
|
|
Du interessierst dich nur für die Proportionalität. Das Problem ist ja, dass du einem Punkt aus einem überabzählbaren Intervall keine Wahrscheinlichkeit zuweisen kannst, sonst wäre die Summe aller Einzelwahrscheinlichkeiten ja unendlich, ausserdem liegt wie du ja schon sagtest die Dichte nicht in [0,1].
Du kannst aber sehr wohl ein kleines Intervall nehmen, und von der Wahrscheinlichkeit sprechen, dass ein Wert aus diesem Intervall eintritt. Jetzt ist P[X in (x, x+delta)] = \int_x^{x+\delta} p(y)dy aber dank Regularität (Lipschitz Stetigkeit ) der Dichte klar abhängig von p(x), und das benutzt du um auf wahrscheinlich/unwahrscheinlich zu schließen ohne das Integral auszurechnen.
/disclaimer: alles aus den Fingern gesogen
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Irdorath am 04.04.2017 12:16]
|
|
|
|
|
|
|
|
|
Okay, also im Endeffekt macht man also nur wirklich davon Gebrauch, dass Ausreißer einen Funktionswert von nahe 0 haben und den ganzen Term gegen 0 laufen lassen, oder?
Dass ich mit kleinen Intervallen eine wirkliche Wahrscheinlichkeit herbeiführen könnte, habe ich zwischendurch auch mal gelesen, aber das macht man hier ja nicht, sondern man nimmt tatsächlich nur die Funktionswerte. Also hat der Term keine Bedeutung wie eine absolute Wahrscheinlichkeit. Oder liege ich da falsch? 
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von homer is alive am 04.04.2017 12:20]
|
|
|
|
|
|
|
|
|
Ja, würde deinen beiden Aussagen zustimmen.
Aber schon die Bedeutung "absoluter Wahrscheinlichkeit" für ein simples diskretes Experiment wie einen Münzwurf ist eher eine philosophische Frage, populär sind bayesianischer und frequentistischer Ansatz.
|
|
|
|
|
|
|
|
|
|
|
Da haste schon recht, die Bezeichnung ist vielleicht auch unglücklich gewählt. Ich meinte damit eigentlich nur was mit F(5) = P(X<5), was ja wirklich eine Wahrscheinlichkeit angibt. Also, besten Dank, das hat mich nicht losgelassen. 
|
|
|
|
|
|
|
|
|
|
|
It's C++ time!
Ich möchte ein Objekt per MPI verschicken, muss es dafür serializen. Weil ich irgendwelche fetten libs vermeiden will und es nur um dieses eine Objekt geht, schrob ich mir die serializer/deserializer Funktionen selbst.
Hier ein funktionierendes Schema:
| |
| Code: |
#include <iostream>
#include <string>
#include <vector>
#include <sstream>
using namespace std;
class test {
public:
test() {};
test(string & sd) {
istringstream iss (sd);
size_t int_size;
iss.read(reinterpret_cast<char*>(&int_size), sizeof(size_t));
x.resize(int_size);
iss.read(reinterpret_cast<char*>(&x[0]), int_size * sizeof(double));
}
string serialize() {
ostringstream buf;
size_t int_size = x.size();
buf.write(reinterpret_cast<char*>(&int_size), sizeof(size_t));
buf.write(reinterpret_cast<char*>(&x[0]), int_size * sizeof(double));
return buf.str();
}
void print() {
for(auto& d: x)
cout << d << ", ";
cout << endl;
}
vector<double> x;
}
int main(int argc, char const *argv[]) {
test t;
t.x = {1,2,13413.2};
t.print();
string p = t.serialize();
test t2(p);
t2.print();
return 0;
} |
|
Es funktioniert und ich bin stolz. Aber, wo ich immer unsicher bin und eure Hilfe brauche, ist der Umgang mit Streams. Binäre Daten über MPI zu verschicken geht wohl am besten mit char* arrays, deshalb bin ich hier über std::string gegangen. Habe ich irgendwo overhead drin, den ich vermeiden kann? Es werden am Ende relativ große Datenmengen (mehrere 10 MB) pro string sein, deshalb würde ich alles möglichst effizient implementieren wollen.
|
|
|
|
|
|
|
|
|
|
|
> Habe ich irgendwo overhead drin, den ich vermeiden kann?
Du kopierst alles mindestens einmal:
x.resize(int_size);
iss.read(reinterpret_cast<char*>(&x[0]), int_size * sizeof(double));
ostringstream buf;
buf.write(reinterpret_cast<char*>(&x[0]), int_size * sizeof(double));
Das return buf.str() sollte durch RVO keine extra Kopie sein.
---
Wenn du wenige Bytes Header vor sehr sehr vielen Bytes Daten tust, kann sich eine Scatter/Gather I/O lohnen, wo man die Daten dann nicht nochmal extra kopieren muss (was meistens zweierlei bedeutet: 1.) Man läuft zum Allocator 2.) Man macht eine Kopie). Ich weiß nicht, ob MPI das kann.
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von csde_rats am 04.04.2017 14:19]
|
|
|
|
|
|
|
|
|
Ich glaube, um es auf MPI Level zu optimieren, dafür ist es dann doch zu wenig performance kritisch.
Zum Kopieren: Kann ich das verhindern? Was meinst du mit RVO?
|
|
|
|
|
|
|
|
|
|
|
RVO = Return Value Optimization.
Wenn du sowas hast:
std::string bar() {
std::string foo = ...;
return foo;
}
Dann würde eigentlich der string foo beim return in den Aufrufer kopiert werden müssen. RVO erlaubt es dem Compiler, foo direkt im Aufrufer weiter zu benutzen, ohne separate Kopie.
--
Die Kopie über den Buffer kannst du m.E. nur mit einigem Aufwand vermeiden, wenn du keinen Scatter/Gather später machen kannst: Wenn die API später halt nur einen einzelnen Speicherbereich verarbeiten kann, aber man mehrere senden möchte, muss man die eben zusammenkopieren (oder schon tief in die Trickkiste greifen-- z.B. wenn man ein sehr großes Array in einem anonymen mmap() liegen hat, kann man das Mapping ein bisschen nach unten wachsen lassen, um dann dort seinen Header reinzukopieren - Zack, Kopie vom großen Array vermieden).
|
|
[Dieser Beitrag wurde 2 mal editiert; zum letzten Mal von csde_rats am 04.04.2017 14:38]
|
|
|
|
|
|
|
|
|
Okay, danke. Kopier ich die Soße halt.
MPI macht richtig Spaß inzwischen.
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von homer is alive
Okay, also im Endeffekt macht man also nur wirklich davon Gebrauch, dass Ausreißer einen Funktionswert von nahe 0 haben und den ganzen Term gegen 0 laufen lassen, oder?
Dass ich mit kleinen Intervallen eine wirkliche Wahrscheinlichkeit herbeiführen könnte, habe ich zwischendurch auch mal gelesen, aber das macht man hier ja nicht, sondern man nimmt tatsächlich nur die Funktionswerte. Also hat der Term keine Bedeutung wie eine absolute Wahrscheinlichkeit. Oder liege ich da falsch?
| |
Ein paar hoffentlich nicht allzu verwirrende Anmerkungen:
- Wenn es dir hilft, kannst du den Term der da steht auch als eine Mehrdimensionale Normalverteilung auffassen, in der die einzelnen Dimensionen unabhängig voneinander sind (in Mathe: Die Kovarianzmatrix ist diagonal). In gewisser Weise berechnest du deswegen nicht ein Produkt von Dichtefunktionen, sondern genau eine Dichtefunktion, nämlich die des Vektors. Und in diesem Fall wird der ganze Vektor unwahrscheinlich wenn mindestens einer der Einträge unwahrscheinlich ist.
- Der Zahlenwert der Dichtefunktion trägt in der Tat keine direkte Semantik, sondern wie Irdorath sagt geht es um Proportionalitäten. Es stimmt aber schon, dass wenn die Dichtefunktion große Werte annimmt, ein Bayesianer gerne darauf wetten würde, dass samples aus der Verteilung zumindest in der Nähe sind. Bedenke: Die Dichtefunktion kann nicht überall groß sein, denn sie muss ja über der Trägermänge zu 1 integrieren und ist nirgendwo negativ. Wenn die Dichte also irgendwo sehr große Werte annimmt, dann heißt das (zumindest für "schöne" Verteilungen), dass es auch Gebiete geben muss, wo sie sehr klein ist, um das "auszugleichen".
- Dichtefunktionen interpretieren wird wie ich finde in Integralen viel einfacher, denn dafür sind sie schließlich in ihrer Funktion als Wahrscheinlichkeitsmaß da. Schau dir den Erwartungswert von einer Zufallsvariable
 über sagen wir den reellen Zahlen an: über sagen wir den reellen Zahlen an:
![TeX: E[X] = \int x \cdot p(X = x) dx](http://chart.apis.google.com/chart?chco=FFFFFF&chf=bg,s,00000000&cht=tx&chl=E%5BX%5D+%3D+%5Cint+x+%5Ccdot+p%28X+%3D+x%29+dx)
Der Erwartungswert kann interpretiert werden als die Zahl, die rauskommt, wenn ich X nur oft genug sample und den Durchschnitt über alle Ergebnisse ausrechne. Um das analytisch auszurechnen mit Hilfe des Integrals rechnest du den "Durchschnitt" über alle Reellen Zahlen aus, die jedoch danach gewichtet werden, wie oft sie aus X rausfallen - und diese Gewichtung ist die Dichtefunktion. Wenn man sich aus dem Fenster lehnen wollte könnte man sagen, dass das Integral dazu da ist, aus der Dichtefunktion die "Proportionalität" rauszukitzeln, die Irdorath anspricht.
|
|
|
|
|
|
|
|
|
|
|
Danke B0rG. Ich hatte im Studium nicht gerade wenig Statistik, allerdings war das grundlegende Zeug schon relativ am Anfang, sodass ich mir deswegen nicht mehr sicher war. Es ging mir jetzt speziell nur um die Semantik des Zahlenwerts (gefällt mir, das so auszudrücken). Ich war nur etwas verwirrt, weil der gute Andrew Ng im Kurs von Wahrscheinlichkeiten sprach, ich mir aber sicher war, dass dies keine sind, allerdings nirgends Informationen gefunden habe, die genau das belegen konnten. Die mehrdimensionale Normalverteilung wurde später noch eingeführt und ist mir auch bekannt.
Insofern bin ich kein Anfänger auf dem Gebiet, aber gut, dass meine Vermutungen hier noch einmal fachmännisch bestätigt und erklärt wurden.
|
|
|
|
|
|
|
|
|
|
|
Schön geschrieben.
Da du gerade hier bist, hast du Leseempfehlungen zu stochastischem Bellman Prinzip? Ansonsten wird es Davis1979:martingale methods in stochastic control.
Außerdem schwächel ich mit mehrdimensionale Markovprozesse in folgendem Sinne: Y und Z jeweils d-dimensionale Markovprozesse, Was sind Bedingungen für den 2d-dimensionalen Prozess (Y, Z) Markov zu sein und was ist der Generator.
Ich würde jetzt naiv und ohne viel Markov Erfahrung eben den Prozess (Y1,..., Yd, Z1,..., Zd) aufziehen und von Hand durchrechnen, aber das wird leicht aufwändig. Vielleicht gibt es da ja ein paar schöne Bedingungen oder so?
|
|
|
|
|
|
|
|
|
|
|
Einfach immer im Bezug auf die Dichte von Wahrscheinlichkeiten zu sprechen ist eine ML-Krankheit und ein bisschen der Tatsache geschuldet, dass das ja "bis auf Normierung" auch irgendwie stimmt. Und Normierungen lässt man ohnehin gerne weg.
Irdorath: Du bist optimistisch . Eine Leseempfehlung kann ich dir leider nicht anbieten, da das nicht mein Gebiet ist. Ich würde jetzt intuitiv mal in Richtung probabilistic Programming suchen und schauen ob's da irgendein Standardwerk gibt, weil ich mir vorstellen kann, dass das da auch Thema ist.
Aus der Hüfte geschossen würde ich außerdem sagen, dass das kombinieren von Markovprozessen die Markov-Eigenschaft eigentlich nicht kaputt machen kann. Du hast ja maximal zusätzliche Informationen, die aber eigentlich nicht wehtun sollten. Weißt du ein Gegenbeispiel?
e/ Oh eins noch: Da das ja Normalverteilungen sind kann man eventuell das Epsilon interpretieren als wie viele Standardabweichungen man vom Mittelwert weg ist oder als Quantil (was bei Normalverteilungen mehr oder weniger das gleiche ist).
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von B0rG* am 04.04.2017 15:55]
|
|
|
|
|
|
|
|
|
(Y_t, Y_{t-1}) mit natürlicher Filtration von Y sollte nicht Markov sein für Zeitpunkte s>t-1, denke mit Y und Z abhängig lässt sich da einiges konstruieren. Unabhängigkeit dürfte wohl reichen, hab ich aber leider nicht. 
/blödes Beispiel, zur natürlichen Filtration ist wohl auch Y_t-1 nicht Markov. Aber so in die Richtung müsste ein Gegenbeispiel wohl konstruierbar sein.
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Irdorath am 04.04.2017 15:55]
|
|
|
|
|
|
| Thema: pOT-lnformatik, Mathematik, Physik XX ( Der XX(X)-Thread. ) |






![AUP [smith] 29.07.2010](./avatare/upload/U1066026--zeratul.png)







