|
|
|
|
|
|
|
|
Brother konnte das bisher nicht. Wir hatten hier im Thread schon mal ein Test mit QR Codes auf Trennblättern, as dann von einem Paperless? Script erkannt wurde.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ok … ich bin neugierig.
Mal angenommen ich wäre so digital aufgestellt wie ihr es seid. Ich komme nachhause, öffne die Post und möchte diese entsprechend digital verwahren. Ich leg das also in meinen Dokumentenscanner drücke auf „scannen“ und das wars? Die digitale Kopie wird in einem großen Ordner abgelegt - zusammen mit Gehaltsabrechnungen, Steuerbescheiden und Versicherungspolicen? Oder kann ich das Ganze evt. beim Scannvorgang schon einem bestimmten Ordner zuweisen, so dass ich später aber eine Ordner übergreifende Suche starten kann?
Was brauch ich um los zu legen? Als Cloud Anbieter hätte ich OneDrive, iCloud und Dropbox anzubieten. Am liebsten wäre mir die Nutzung von OneDrive. Kann man damit arbeiten?
Welches Gerät würdet ihr empfehlen? Wichtig wäre mir, dass ich computerlos scannen kann. Ich habe beim Überfliegen jetzt was von einem „ix“ gelesen. Wäre das auch eure Empfehlung?
Empfiehlt es sich dann trotzdem spezielle Software zu installieren? Evt. auch um später die Suche komfortabler zu gestalten?
Das sind wahrscheinlich Fragen, die hier alle paar Seiten gestellt werden - ich werde den Thread die Tage auch nochmal genauer durch lesen.
Vielleicht packt ihr die Antworten in den Startpost?
Ich sage im Voraus schonmal vielen Dank.
Edit: nach kurzer Recherche bin ich also auf der Suche nach einem Gerät, welches ohne aktive PC Verbindung ein durchsuchbares PDF erstellen kann. Gibt‘s das überhaupt? 
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von dantoX am 19.03.2022 13:34]
|
|
|
|
|
|
|
|
|
Vorab: ja, es geht, dass du einfach deine Post durch den Scanner jagst und diese dann ohne Rechner archiviert wird.
Es gibt Scanner (wie der ix1300), die auf eine Cloud scannen können. Dann liegt aber deine ganze Post im Netz in fremder Hand.
Zudem musst du dir ja die Frage stellen, wie du die Post dann weiter verwendest und insbesondere wiederfindest. Denkbar wäre natürlich, dass du in die Cloud scannst und einfach ohne extra Software verschiedene Ordner verwendest. Das ist - je nach Scanner - möglich.
Dann hast du aber deine Post als PDF ohne ocr mit einem Dateinamen der dir abgesehen vom Datum nicht weiterhelfen wird.
Ich wollte es etwas bequemer und a) ocr b) ein Programm mit dem ich das ganze sortieren und durchsuchen kann (DMS).
Hier wird zumeist paperless-ngx verwendet.
Das einfachste dafür wäre bei nicht vorhandener Software n Synology Nas mit docker Funktion und eben n passenden Scanner. Wenn du aufs Nas und nicht in die Cloud scannen willst kannst du denn ix1300 aber wieder vergessen. Ich habe stattdessen den Brother 1700 und bin bisher sehr zufrieden
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Poerger am 19.03.2022 13:34]
|
|
|
|
|
|
|
|
|
Ganz klassisch nimmt man einen Dokumentenscanner, da wiederum ist der Klassiker Fujitsu ScanSnap iXxxxx, den genauen Typen, der aktuell empfohlen wird, weiß ich nicht.
Ich hab mir ein Multifunktionsgerät gekauft, dass auch bis zu 50 Seiten automatisch einziehen und scannen kann. Achte auf beidseitigen Scan in einem Durchzug, iirc ist das Stichwort "ADF".
Des Weiteren sollte dein Scanner in der Lage sein, die Dateien direkt in einen Netzwerkordner oder Cloud Dienst zu legen.
Einige Scanner können direkt OCR (Texterkennung des gescannten Dokuments) ausführen und legen diesen Text als Metaebene in die Datei (PDF). Damit hast du durchsuchbare PDFs und je nach z.B. Clouddienst oder File Explorer reicht das schon, um ein PDF auf seinen Inhalt zu durchsuchen. Google Drive macht übrigens eigenes OCR (Texterkennung des Dokuments), heftet das aber nicht ans PDF an.
Du kannst nun also alle ankommenden PDFs in deinem Cloud Drive in Ordner wegsortieren und gut.
Oder du lässt alle in einem Ordner und verlässt dich auf die Inhaltssuche.
Ein zweitee Weg, so setze ich es aktuell auf, ist ein Dokumentenmanagementsystem. Hier wird das quelloffene Paperless NGx empfohlen. Das lässt du auf einem kleinen Server laufen. Der Scanner legt die neuen Dokumente in den "consume" Ordner von Paperless, welches diese erkennt , OCR (was mein MuFu-Gerät nicht kann) drauf ausführt und ins PDF schreibt. Paperless hat dann eine Weboberfläche, in deren Inbox du dann deine neuen Dokumente siehst. Die kannst du mit Tags versehen, was flexibler als Ordner ist. Du kannst auch die Art des Dokuments, Korrespondenten und andere Sachen eintragen und später, neben der Volltextsuche, danach filtern und suchen.
Bei mir läuft Paperless auf nem Raspberry Pi 4, was okay ist aber etwas langsam mit dem OCR.
Als Backup könntest du dann deine Paperless Ordner und Configs in die Cloud spiegeln.
Und was ist mit den Originaldokumenten? Leider sollte man weiterhin bestimmte Dokumente im Original behalten. Hier wird empfohlen, einen Paginierstempel zu benutzen, mit dem du fortlaufende Nummern auf deine Dokumente stempelst und sie dann die Reihe nach (!) einfach in denselben Ordner tust. Ist ein Ordner voll, kommt der nächste und du schreibst den Nummernbereich auf den Ordnerrücken. Suchen tust du ein Dokument dann erstmal am Rechner. Hast du's gefunden, kennst du die laufende Nummer und weißt, in welchem Ordner du es findet. Bei Paperless kann man übrigens auch diese laufende Nummer dem Dokument zuordnen.
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von MCignaz am 19.03.2022 13:53]
|
|
|
|
|
|
|
|
|
|
Welcher Scanner kann den selber OCR?
|
|
|
|
|
|
|
|
|
|
|
|
Dachte diese ScanSnaps, oder ist das nur mitgelieferte Software? Jetzt wo ich drüber nachdenke, wohl letzteres.
|
|
|
|
|
|
|
|
|
|
|
|
Das macht die Software auf dem Rechner oder die Cloud
|
|
|
|
|
|
|
|
|
|
|
Ok. Also so eine all-in-one Lösung gibt es noch nicht. Schade. Ich hatte die naive Vorstellung, dass ich das Gerät hinstelle, mit OneDrive verninde, 6-7 Ordner anlege und dann per Touchscreen direkt in diese Ordner scanne und das ganze dann schon ein durchsuchbares ocr pdf wird.
Server aufsetzen (ob groß oder klein) etc. ist mir aktuell noch zu viel Aufwand.
Ich würde erstmal mit der Cloud anfangen und wenn ich merke, dass ich das wirklich nutze und es läuft vielleicht auch mal ein NAS anschaffen - aber das wäre Schritt zwei und nicht Schritt eins.
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von dantoX am 19.03.2022 14:31]
|
|
|
|
|
|
|
|
|
|
Wenn gu google drive als cloud nimmst geht das auch. Dann hast du - in der cloud - ocr. Da das ocr nicht mit der pdf verknüpft ist, müsstest du bei nem systemwechsel auf ein nas o.ä. später über die scans nochmal ocr laufen lassen.
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von [KDO2412]Mr.Jones
Welcher Scanner kann den selber OCR?
| |
Der hier z.B
Alles eine Frage des Geldes
| | Zitat von dantoX
Ok. Also so eine all-in-one Lösung gibt es noch nicht. Schade. Ich hatte die naive Vorstellung, dass ich das Gerät hinstelle, mit OneDrive verninde, 6-7 Ordner anlege und dann per Touchscreen direkt in diese Ordner scanne und das ganze dann schon ein durchsuchbares ocr pdf wird.
Server aufsetzen (ob groß oder klein) etc. ist mir aktuell noch zu viel Aufwand.
Ich würde erstmal mit der Cloud anfangen und wenn ich merke, dass ich das wirklich nutze und es läuft vielleicht auch mal ein NAS anschaffen - aber das wäre Schritt zwei und nicht Schritt eins.
| |
Doch das müsste mit dem oben genannten gehen, man muss halt wissen ob einen das Geld dafür Wert ist.
Wir haben auf der Arbeit mehrere, größere Canon Drucker und die Scanner der Drucker sind wirklich auch top.
Damit digitalisieren wir unseren Rechnungseingang/Ausgang ins Netzwerk und die Dokumente werden im Scanner mit OCR verarbeitet
Ich habe zuhause einen Brother ADS 1700 und da nervt mich ,dass er öfters mal Blätter schief einzieht oder auch mal doppelte einzieht, gerade wenn mehrere Seiten geknickt per Post kamen.
Wenn der mal kaputt geht, werde ich auch mehr Geld in die Hand nehmen.
|
|
|
|
|
|
|
|
|
|
|
Ehrlich gesagt hab ich nen Scanner hier der direkt in mein Google Drive scannen kann. Und benutzen tu ich ihn trotzdem nicht.
Erstmal muss 99% der Post nicht aufgehoben werden. Aufheben musst du ja am Ende doch nur Kram der für die Steuererkläung relevant sein könnte. Alles andere kann man lesen und wegschmeißen. Und die paar Zettel die da übrig bleiben scanne ich schnell im Flur/Wohnzimmer/Esstisch mit dem Smartphone. Das Ergebnis ist mehr als gut genug und ich kann es direkt in den oder die richtigen Ordner legen ("/Steuer/2022/" und "/Haus/Rechnungen/").
Kostet nix, das Ergebnis is näherungsweise genausogut, für meinen Usecase ehrlich gesagt besser. Ich brauch keinen Stellplatz für noch ein blödes Elektrogerät (davon hab ich eh schon vielzuviele). Und die richtigen Dokumentenscanner sind auch nicht 100% wartungsfrei. Der ADF in meinem Canon haben nicht mehr den besten Grip, weil die Gummierung staub aufnimmt. Kann man reinigen, aber nervt. Das SOHO-Gerät von Brother das ich mal von der Firma zu Entwicklungszwecken mit nach Hause bekommen hab ist da besser, aber auch da nimmt der Grip irgendwann ab.
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Teh Ortus am 19.03.2022 21:30]
|
|
|
|
|
|
|
|
|
Ich habe jetzt immer wieder bisschen mitgelesen, wenn über paperless-ng(x) diskutiert worde. tl;dr: für mich -> wer bisher jahrelang mit Ordnerstruktur und Dateinamen gearbeitet hat und den Zugriff auch offline auf gewissen Geräten haben will (z.B. Laptop im offline-Urlaub um die Steuern zu machen) und aus genau dem Grund auf Ordnerstrukturen udn Dateinamen setzen muss, lässt die Finger davon. Richtig?
/hier übrigens ein ix500 im Einsatz. Rollen ersetzt (war bitter nötig). OCR geht nur via Software. Das in die Cloud scannen via Wifi ginge, aber nicht in maximaler Scanqualität (und eben ohne OCR), was es für mich unbrauchbar macht. Ist schade, aber ich löse das sehr einfach: ich sammle einfach alles und scanne alle paar Wochen am PC. Damit kann ich gut leben.
Manchmal fände ich aber einen günstigen, super einfach zu bedienenden Dokumentenscanner für meine Mutter resp. ihre Post super  Blatt einlegen, udn ich habs nachher hier in der Cloud bei mir. Und sie muss nur einen Knopf drücken und fertig. Aber das sind Wohlstandsprobleme. Blatt einlegen, udn ich habs nachher hier in der Cloud bei mir. Und sie muss nur einen Knopf drücken und fertig. Aber das sind Wohlstandsprobleme.
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von dino the pizzaman am 21.03.2022 8:33]
|
|
|
|
|
|
|
|
|
| | Zitat von dino the pizzaman
Ich habe jetzt immer wieder bisschen mitgelesen, wenn über paperless-ng(x) diskutiert worde. tl;dr: für mich -> wer bisher jahrelang mit Ordnerstruktur und Dateinamen gearbeitet hat und den Zugriff auch offline auf gewissen Geräten haben will (z.B. Laptop im offline-Urlaub um die Steuern zu machen) und aus genau dem Grund auf Ordnerstrukturen udn Dateinamen setzen muss, lässt die Finger davon. Richtig?
| |
Das...kommt drauf an. Was du willst.
paperless (egal, was für Buchstaben dranhängen) ist einfach eine Software, die dir einen Webservice bereitstellt, um Dokumente anzuschauen, suchen, zu kategorisieren, herunterzuladen. Also eine Webseite, mit Login und Gedöns. Wenn man das nur im heimischen LAN laufen lässt, kann man den Login auch wegkonfigurieren. Wenn du das aus dem Internet erreichen willst, dann hostest du das extern (würde ich aber nicht empfehlen) oder richtest dir zuhause ein VPN ein.
paperless sieht dann so aus:
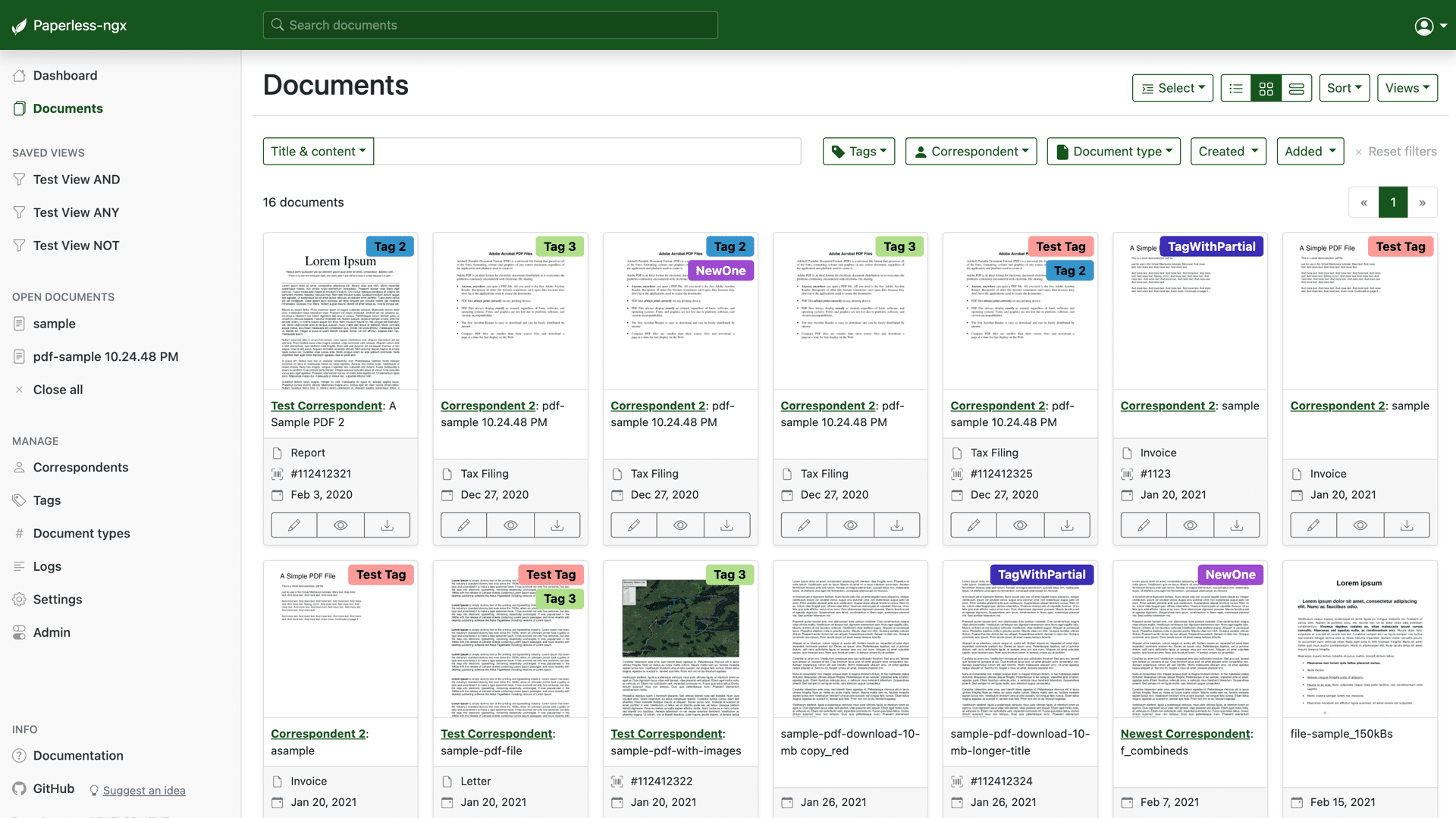
Eine Liste mit Dokumenten und Suchfilter. Diese Filter sind sehr gut. Du kannst direkt nach bestimmten Absendern suchen, bestimmte Tags, Datumsbereiche oder auch im Volltext aller Dokumente. Deutlich schneller und präziser als bspw. eine Suche im Windows Explorer. Du musst keine Kenntnisse mehr über Ordnerstrukturen mitbringen. Darum ist es auch für Familien geeignet, weil nicht nur mehr eine Person das Wissen über die Fundorte bestimmter Dokumente hat.
paperless arbeitet mit zwei Ordnern auf Dateistrukturebene: ein Consumer-Ordner und ein Media-Ordner (das können Ordner auf dem Rechner sein, wo auch paperless läuft, das können natürlich auch Netzlaufwerke sein).
In den Consumer verschiebt man Dokumente (pdf), die paperless verarbeiten soll, denn die Datenbank mit Information wie Absender, Tags etc. muss ja erzeugt werden. paperless macht OCR und wendet dann Regeln an, die du auf der Webseite festlegen kannst, wie ein Dokument zu verarbeiten ist. Bspw. könntest du sagen "wenn das Wort Rechnung vorkommt, dann gib den Tag Finanzen". Oder "wenn der Begriff 'Telekom' gefunden wird, dann ist dies der Absender". Ganz typisch: "das erste gefundene Datum ist das Datum des Dokuments". Diese Informationen kannst du auf der Webseiten aber auch händisch korrigieren. Danach legt paperless das Dokument in den Media-Ordner und leert den Consumer. Wenn du deine Struktur übertragen willst, müsstest du zunächst alle Dokumente in den Consumer-Ordner legen.
Es gibt zwei Alternativen zu diesem Ordner: Direktupload über das Webinterface oder du gibst paperless Zugriff auf ein IMAP-Mailpostfach und dort einen Ordner, aus dem automatisch Anhänge verarbeitet werden sollen.
Es ist aber nicht so, dass paperless die Dokumente einfach in den Media-Ordner reinwirft und da dann ein Wust an PDFs rumfliegt, den man nicht verstehen kann. paperless ist so designt, dass nach einem Ausfall von paperless (oder wenn man etwas anderes benutzen will), der Media-Ordner benutzbar bleiben soll. Deshalb legst du in der Config Regeln ab, wie der Media-Ordner aussehen soll. D.h. Unterordner und Dateinamen.
Bei mir werden die Dokumente bspw. zunächst in Ordner nach Jahren sortiert, danach nach Monaten und danach ist der Dateiname "Datum Absender.pdf". Es gibt noch ein paar Möglichkeiten, die die generierten Metadaten berücksichtigen. Man kann also problemlos in den Media-Ordner rein und dort von Hand drin suchen. paperless soll diese Suche aber viel einfacher machen (und das schafft es).
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Armag3ddon am 21.03.2022 9:25]
|
|
|
|
|
|
|
|
|
|
Mit welchen Standards scannt ihr? 150DPI? Welche Komprimierungsstufe?
|
|
|
|
|
|
|
|
|

|
| | Zitat von Armag3ddon
[Erläuterung zu paperless-ng]
| |
Ziemlich geile Sache.
Was spräche dagegen einfache eine externe Festplatte oder gar einen USB Stick an meine Fritz.Box zu stecken und dort alles hinzuscannen?
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von dantoX am 21.03.2022 11:26]
|
|
|
|
|
|
|
|
|
| | Zitat von Feelgood Managerin
Mit welchen Standards scannt ihr? 150DPI? Welche Komprimierungsstufe?
| |
Man sollte mit 300DPI scannen, damit die OCR Software ordentlich arbeiten kann. So ist das zumindest bei Scan/OCR Dienstleistern a la Ricoh und DHL der Standard.
|
|
|
|
|
|
|
|
|
|
|
|
Danke für die Infos. Ich muss mir das vermutlich einfach mal anschauen. Ich habe schon einige bestehende Workflows wie bspw. Rechnunge für die Firmenbuchhaltung werden bei Erfassung in der Buchhaltung (nicht beim scan) mit ner zusätzlihcen ID im Dateinamen versehen und woanders hinverschoben. Das klappt alles super und da brauche ich auch keine Unterstützung von einem DMS. Gleichzeitig wäre es aber fancy, wenn das System mit diesen Änderungen klar käme. Oder so Krempel wie eine grundsätzliche Unterteilung von meinen Dokumenten und Dokumenten meiner Mutter (welche ich pflege, dennoch aber getrennt habe(n muss); auch wegen Ablage in ihrer Dropbox usw...
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von dantoX
| | Zitat von Armag3ddon
[Erläuterung zu paperless-ng]
| |
Ziemlich geile Sache.
Was spräche dagegen einfache eine externe Festplatte oder gar einen USB Stick an meine Fritz.Box zu stecken und dort alles hinzuscannen?
| |
Nichts. Wenn deine Frage sich aber konkret auf paperless bezieht: du brauchst ein System (Rechner, Raspberry Pi, NAS, ...), wo paperless als Software direkt drauf läuft. Das kann die fritzbox nicht. Aber natürlich könnte dieses System auf einen Ordner auf der fritzbox zugreifen und sich von dort Dokumente holen oder die wieder dort ablegen.
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von Armag3ddon
| | Zitat von dantoX
| | Zitat von Armag3ddon
[Erläuterung zu paperless-ng]
| |
Ziemlich geile Sache.
Was spräche dagegen einfache eine externe Festplatte oder gar einen USB Stick an meine Fritz.Box zu stecken und dort alles hinzuscannen?
| |
Nichts. Wenn deine Frage sich aber konkret auf paperless bezieht: du brauchst ein System (Rechner, Raspberry Pi, NAS, ...), wo paperless als Software direkt drauf läuft. Das kann die fritzbox nicht. Aber natürlich könnte dieses System auf einen Ordner auf der fritzbox zugreifen und sich von dort Dokumente holen oder die wieder dort ablegen.
| |
Ok. Mal angenommen ich hätte gern so einen Raspberry Pi - voll vorkonfiguriert. Wieviel Goldtaler (Schokolade) würdest du dafür nehmen? Rein hypothetisch natürlich.
Theoretisch könnte ich den Raspberry PI doch auch zur Verwaltung des NAS nutzen (also, dass ich da dran, dann einen USB Speicher hänge) oder sind die Dinger dafür zu schwach um beides zu können?
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von dantoX am 21.03.2022 11:42]
|
|
|
|
|
|
|
|
|
Der Raspberry wäre die Lösung, wenn man ein Gerät haben will, was sehr wenig Strom frisst und unabhängig von jeweiligen Speicherlösungen ist. Selbst vorgefertigt: um ein bisschen Administration kommt man da aber nicht herum, weil du zumindest Netzlaufwerke bei dir konkret im LAN einrichten müsstest.
Ich weiß auch leider nicht, ob der Raspi gerade die günstigste Alternative ist. Da ich jetzt sehe, dass der Raspi 4 inzwischen stolze 80 € kostet.  Vielleicht ist daher ein NAS mit Docker, was andere hier benutzen, die bessere Wahl (nach dieser Anleitung). Ein NAS selbst ist ja auch wieder nur ein Gerät, was du an Strom und Netzwerk anschließt und dann freigegebene Ordner oder Dienste konfigurierst. Ich habe dafür hier eine WD Cloud stehen (WD Cloud EX2, ~150€ ). Ein NAS kommt mit einem eingebauten Rechner, der als Controller bereitsteht. Das willst du wahrscheinlich nicht selber mit einem Pi basteln. Vielleicht ist daher ein NAS mit Docker, was andere hier benutzen, die bessere Wahl (nach dieser Anleitung). Ein NAS selbst ist ja auch wieder nur ein Gerät, was du an Strom und Netzwerk anschließt und dann freigegebene Ordner oder Dienste konfigurierst. Ich habe dafür hier eine WD Cloud stehen (WD Cloud EX2, ~150€ ). Ein NAS kommt mit einem eingebauten Rechner, der als Controller bereitsteht. Das willst du wahrscheinlich nicht selber mit einem Pi basteln.
Du kannst natürlich auch USB-Gedöns an den Pi anschließen. Voraussetzung dürfte sein, dass diese Geräte eine eigene Stromversorgung haben, weil der Pi doch etwas schwach am USB-Ausgang bedient. Deine größte Gefahr ist dann jedoch Hardwareausfall. Ein richtiges NAS bietet dir ein RAID, also mindestens eine gespiegelte Festplatte. Du willst ja nicht, dass dein USB-Stick von heute auf morgen kaputtgeht und alle deine Dokumente weg sind. Also müsstest du wieder eine handgestrickte Backuplösung umsetzen.
Vielleicht wäre für dich das sorgloseste Paket eine Synology Disk Station mit Docker, wo man dann nach der Anleitung paperless-ngx drauf installiert. Diese Installation ist eigentlich auf einem Niveau, dass man dich da durchleiten kann, wenn es überhaupt Probleme gibt, und nicht Großaktionen mit Hardwareversand gestartet werden müssen. Ich weiß nicht, was man für ein Modell da braucht, aber das das kostet wahrscheinlich auch alles weniger gerade, weil der Pi so teuer ist. Den benutze ich vor allem, weil ich da drauf auch noch Heimautomation und PiHole laufen lasse und er damit schon vorhanden war.
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Armag3ddon am 21.03.2022 12:07]
|
|
|
|
|
|
|
|
|
Ok. Danke Dir.
Dann weiß ich welche Ausgaben demnächst anstehen. Fange ich doch mal mit einem NAS an 
|
|
|
|
|
|
|
|
|
|
|
|
Denk an ein Backup der Dateien auf dem NAS an einem anderen Ort.
|
|
|
|
|
|
|
|
|
|
|
am besten gleich 2 Nas kaufen!
(tausche gerade backup nas ds118 gegen ein ds720 um)
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von Teh Ortus
Ehrlich gesagt hab ich nen Scanner hier der direkt in mein Google Drive scannen kann. Und benutzen tu ich ihn trotzdem nicht.
Erstmal muss 99% der Post nicht aufgehoben werden. Aufheben musst du ja am Ende doch nur Kram der für die Steuererkläung relevant sein könnte. Alles andere kann man lesen und wegschmeißen. Und die paar Zettel die da übrig bleiben scanne ich schnell im Flur/Wohnzimmer/Esstisch mit dem Smartphone. Das Ergebnis ist mehr als gut genug und ich kann es direkt in den oder die richtigen Ordner legen ("/Steuer/2022/" und "/Haus/Rechnungen/").
Kostet nix, das Ergebnis is näherungsweise genausogut, für meinen Usecase ehrlich gesagt besser. Ich brauch keinen Stellplatz für noch ein blödes Elektrogerät (davon hab ich eh schon vielzuviele). Und die richtigen Dokumentenscanner sind auch nicht 100% wartungsfrei. Der ADF in meinem Canon haben nicht mehr den besten Grip, weil die Gummierung staub aufnimmt. Kann man reinigen, aber nervt. Das SOHO-Gerät von Brother das ich mal von der Firma zu Entwicklungszwecken mit nach Hause bekommen hab ist da besser, aber auch da nimmt der Grip irgendwann ab.
| |
Das heißt du scannst mit Adobe scan Idee Office lens und legst dann alles manuell ab, oder hast du noch ein dms in irgendeiner Form?
Das wäre nämlich exakt das was ich suche.
Aktuell scanne ich alles mit Adobe scan in mein Google drive, aber ich hätte gerne OCR in den PDFs
|
|
|
|
|
|
|
|
|
|
|
Ich benutze die "Scan"-Funktion von Google Drive. Office Lens machte auch einen guten Eindruck.
Ne zeitlang habe ich absurderweise die App von HP für meinen MuFu-Drucker verwendet. Drucker zum Scannen gekauft, App ausprobiert, die Scan-Funktion der MuFu nicht mehr verwendet
Die Scanfunktion von Google Drive hat (logischerweise) die am besten integrierte Ordnerauswahl.
|
|
|
|
|
|
|
|
|
|
|
Danke - ich habe aber leider gar keine Ahnung was genau ich damit machen muss
Ich bin der erwähnte linux dau.
Auch die Hinweise in der Dokumentation zu paperless hilft mir irgendwie nicht weiter. Hab paperless mit docker installiert. Irgendwer n Fingerzeig, wie ich das am einfachsten auf die Kette bekomme?
|
|
|
|
|
|
|
|
|
|
|
| | Zitat von Poerger
Danke - ich habe aber leider gar keine Ahnung was genau ich damit machen muss
Ich bin der erwähnte linux dau.
Auch die Hinweise in der Dokumentation zu paperless hilft mir irgendwie nicht weiter. Hab paperless mit docker installiert. Irgendwer n Fingerzeig, wie ich das am einfachsten auf die Kette bekomme?
| |
Schritt für Schritt:
Du brauchst die Kommandozeile (Terminal) offen.
Erstmal musst du die Software installieren. Wenn dein paperless in Docker läuft, kannst du die auch im Docker Container installieren: https://www.tecmint.com/install-run-and-delete-applications-inside-docker-containers/
Zunächst updaten wir alle Paketinformationen, damit du immer die neusten Versionen installierst:
Wir brauchen Python3 und Java - beides absolute Standardsoftware.
Du kannst testen, ob Python3 schon drauf ist, indem du einfach "python3 --version" eingibst. Wenn da eine Versionsnummer kommt, musst du das nicht installieren.
Ansonsten: https://docs.python-guide.org/starting/install3/linux/
Danach brauchst du pip. Das ist ein Paketmanager für Python, mit dem Python-Module installiert werden. Testen, ob das schon da ist: "python3 -m pip3 --version"
Ansonsten:
| |
| Code: |
sudo apt install python3-pip |
|
Danach brauchst du Java. Test: "java --version".
Ansonsten:
| |
| Code: |
sudo apt install default-jre |
|
Danach installieren wir die 3 Python-Module, die es braucht:
| |
| Code: |
python3 -m pip install zxing pypdf4 pillow |
|
Kontrolle mit "python3 -m pip list".
Danach brauchst du das Python-Script PdfQRSplit.
Das muss irgendwo im Dateisystem abgelegt werden. Das kann auch direkt im paperless-Ordner sein. Entweder nimmst du den grafischen Dateibrowser, der sich wie bei Windows bedient oder du navigierst in der Kommandozeile zum Ordner: https://linuxhint.com/navigate-linux-terminal/
Du kannst einfach eine neue Textdatei anlegen, die dann PdfQRSplit.py nennen. In der Kommandozeile, wenn man im gewünschten Ordner ist, ginge das über "nano PdfQRSplit.py". Den Inhalt kannst du von github direkt kopieren: https://raw.githubusercontent.com/adlerweb/PdfQRSplit/master/PdfQRSplit.py
Danach nimmst du meinen Codeschnipsel aus dem Post und legst das in eine neue Datei. Z.B. "schneiden.sh" (über Kommandozeile dann wieder "nano schneiden.sh"). In diesem Code musst du eine Zeile anpassen:
| |
| Code: |
python3 /pfad/zu/PdfQRSplit/PdfQRSplit.py "$DOCUMENT_SOURCE" -p "$DOCUMENT_NAME" -s "schneiden" |
|
Nämlich den Pfad zum PdfQRSplit.py eintragen.
Danach musst du der Scriptdatei die Rechte geben, dass die ausgeführt werden darf:
| |
| Code: |
sudo chmod +x schneiden.sh |
|
Dieses Shell-Script müssen wir jetzt an paperless geben, damit das vor der Verarbeitung von neuen PDFs durchlaufen kann.
Das muss in der config von paperless passieren: https://paperless-ngx.readthedocs.io/en/latest/configuration.html
Beachte den Hinweis oben: If you run paperless on docker, paperless.conf is not used. Rather, configure paperless by copying necessary options to docker-compose.env.
Also entweder arbeitest du in paperless.conf oder in der Datei docker-compose.env (die man ggf. neu anlegen muss). Darin braucht es einen neuen Eintrag "PAPERLESS_PRE_CONSUME_SCRIPT=..." (in der Dokumentation hier beschrieben).
Wenn das Script im paperless-Ordner liegt, wäre das also einfach
| |
| Code: |
PAPERLESS_PRE_CONSUME_SCRIPT=./schneiden.sh |
|
Geht auch das absoluter Pfad, der fängt mit / an.
Wenn du das ohne paperless testen willst:
| |
| Code: |
sh schneiden.sh pfad/zum/pdf.pdf |
|
Danach wäre paperless einmal neuzustarten und es sollte klappen. Zum Test könntest du ein paar Blätter scannen, den Barcode dazwischenlegen und dann z.B. über die Weboberfläche von paperless hochladen und dort den Log beobachten (Protokoll). Dort müsste dann "[INFO] [paperless.consumer] Executing pre-consume script" oder sowas auftauchen.
|
|
[Dieser Beitrag wurde 2 mal editiert; zum letzten Mal von Armag3ddon am 22.03.2022 10:02]
|
|
|
|
|
|
|
|
|
Vielen Dank für die ausführliche Antwort und Anleitung!
Bevor ich das angehe wollte ich ein Backup von meinem Dokumenten machen (be or ich da noch was versaue) - und ehrlich gesagt stehe ich da ebenfalls vor wie n' Ochse vorm Berg 
Du hast nicht evt ne ähnlich detaillierte Anleitung wie ich am einfachsten n Backup mache bzw dein Backup Script aus deinem post oben verwende?
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Poerger am 22.03.2022 16:21]
|
|
|
|
|
|
|
|
|
Mein Backup Script hilft dir natürlich nur, wenn du auch mein Setup hast. Ich betreibe meine eigene nextcloud und da lade ich die Dokumente verschlüsselt hoch. Wenn du dieses Setup hättest, wäre das Script trivial einzurichten.
Ich vermute aber mal, dass du keine nextcloud hast? Dann ist die Frage, wie deine persönliche Backuplösung aussehen soll. Du hast ja einfach den Media-Ordner von paperless, wo alle Dokumente in Ordnerstrukturen als PDFs rumliegen. Das kannst du nach Belieben backuppen und ggf. auch einfach eingebaute Backup-Lösungen eines NAS benutzen oder sowas.
|
|
[Dieser Beitrag wurde 1 mal editiert; zum letzten Mal von Armag3ddon am 22.03.2022 16:50]
|
|
|
|
|
|
| Thema: Fuck you Registratur ( Unterlagen ordnen für Dummies... ) |



![[KDO2412]Mr.Jones](./avatare/mrjones2.gif)